
在前面一篇中,已经看过许多直观的递归的例子,在这篇里,将分析两个经典的递归问题,阶乘与菲波那契数列数列,在此过程中,还将对比递归与循环(迭代)间的异同,探讨递归与内存中的栈的关系,以及递归的效率等问题。
如无特别说明,示例使用的是 Java,IDE 则为 Eclipse。
阶乘(factorial)
阶乘大家应该都很熟悉了。下面是一些简单例子:2!= 2*1=2用一个简单的循环就可以把它写出来。不过我们现在打算用递归来写。3!= 321=6
两种情形(case)
递归通常有两部分,一是基本情形(base cases),二是递归情形(recursive cases)。发现 case 这个词不好翻译~大家知道是怎么回事就好了,跟 switch 语句中的 case 一个意思。(我也不想去查证标准的翻译究竟是怎样了~)递归基本可表述成以下类似的结构:注:上面的 cases 是复数,即无论是基本情形还是递归情形都可能是一个或多个。
递归调用(参数) { if (基本情形) { // ... // 完成,收工 } else { // 递归情形 // ... 递归调用(新参数); } }因此,写递归程序一是明确基本情形,二是找出递归情形。
基本情形(base case)
对阶乘而言,0!= 1,这就是我们的基本情形。当然你可能认为 1!= 1 才是 base case,这样也 OK,这里不打算去争论这些。据此,我们就可以写出如下代码:
static int factorial(int num) {
if (num == 0) {
return 1;
} else {
// TODO
}
}
递归情形(recursive case)
好了,现在看递归模式。这与上一篇中那个捧着画框的蒙娜丽莎模式非常像:观察 3!与 2!=2*1 就不难看出,3!=3*2*1=3*(2!),即 3!建立在 2!的基础上,推广至更一般的情况,我们有:据此,就可以完成程序了:N! = N * (N – 1)!
static int factorial(int num) {
if (num == 0) {
return 1;
} else {
return num * factorial(num - 1);
}
}
你可以把“num - 1”写成“--num”,这样看上去更紧凑。不过,如果你用代码质量检查工具 sonar 去检查的话,它会抱怨你这种用法。事实上,如果你不小心写成了“num--”,就变成无限递归了,你将收到一个 stack overflow 的错误。所以,老实写成“num - 1”也许才是最好的。
另:阶乘增长是很快的,用 int 的话很快就会溢出。
递归 vs 循环(迭代, iteration)
我们可能更加习惯比如以 for 或者 while 循环写就的代码,但这两种方式其实区别不大。兜圈子的游戏
飞去来器(boomerang)又名回旋镖、自归器、飞去飞来器等其它名称,顾名思义就是飞出去以后兜个圈子后又会再飞回来。(图片来自百度百科)
你一次次反复地把它丢出去,它也会一次次的回来。
递:从递增,递减,递推等词语中,它有反复地,一次又一次地,一个接一个的等意思;从某种意义上说,无论是迭代还是递归,两者都是在兜圈子,下图展示了这一点:归:回来

迭代在 while 语句块中兜圈子,递归则不过是在方法层面上兜圈子,因此都能达到反复执行某些代码的目的。
所以,递归也是一种循环,我们一般意义上说的循环其实应该叫迭代。
递减与终止条件
此外,两者都有类似的终止条件(上图蓝线部分)以及一个递减操作(上图黄线部分)。当然也可能是递增到某个终止条件,总之是要往终止条件靠近。如果无法终止,一个出现死循环,一个则是无限递归。
无限递归通常很快会以栈内存溢出(stack overflow)而终止。总之,不能终止的话都将导致很严重的后果。前面说到,如果不小心把自减--写在变量后面,死循环如果有在块中不断创建对象,也会引发堆内存不足;另一情况则是只是修改本地同一个变量,这样内存占用不会上升,但 CPU 会一直处于高负荷,甚至导致其它进程乃至整个系统假死。
也即先传递值,后自减(写在后面就是后自减),这样就导致了传递的还是原来的值。那么就会引发以下错误:

stackoverflow.com 这个著名的问答网站我想很多人都很熟悉了。经上分析,迭代与递归很相似,那么现在问题来了:
递归迭代哪家强?
递归在方法级别上循环,所以迭代能做的事,它也能做;那么递归能做的事,迭代是不是也能做呢?
- 如果是简单循环,迭代自然也是能做了。
实际上它还更擅长,它的效率要高于递归。2. 如果是复杂的情况,迭代虽然也能做,但做起来可能就是困难重重了。注:有种尾递归优化技术据说能使得递归的效率不逊于迭代,但另一方面,似乎并非所有实现了递归机制的语言都有这种优化,所以说迭代效率要高于递归基本上是没什么问题的。
简单地断言迭代不能完成某些递归能完成的事,这恐怕有点武断。这个问题有点复杂,我看到有些说法是:如果迭代也能完成某些复杂递归才能做到的事,那么,在迭代体的内部,它可能已经不知不觉引入了某种在递归机制中才有的结构,比如类似于栈(stack)的结构,那么,这与递归又有什么实质区别呢?在这些问题上,递归的优势也许正是在于它无需引入这样的结构,从而降低了复杂度。《黑客与画家》一书中也提到一种说法:"任何 C 或 Fortran 程序复杂到一定程度之后,都会包含一个临时开发的、只有一半功能的、不完全符合规格的、到处都是 bug 的、运行速度很慢的 Common Lisp 实现。"
这里要表达的大概也是这样的意思。
注:这些问题比较深奥,因个人才疏学浅,无法对上述说法作为判断,仅当参考,不作为结论。
递归与栈(stack)
栈对递归是必不可少的结构。准确地讲,方法调用离不开栈,递归不过是一种特殊的方法调用,即所谓的“自己调用自己”。从阶乘程序中可以看到,else 块中又调用了它自己,这也是我们通常对于递归的理解。自己调用自己这常会让有些人觉得困惑,或者觉得这种机制很奇特,不好理解。
如果试图自己抓着自己的头发,从而把自己提起来,显然是办不到的。可以在 base case 中设置一个断点,以 debug 模式下跑一下,如下,求 factorial(2):

层叠的方法其实就是一个形象的 stack,从上图中最下面往上走,main 方法调用了 factorial,factorial 则又调用了两次它自己。
可以看到 26 行调用了 21 行处的代码,21 行处的代码又再次调用了自身,最终停在了 19 行我们设置的断点上。main 方法在 26 行处调用了另一个方法 factorial,这导致了 main 方法被压栈(push),也即暂停了 main 方法的执行,转而去执行 factorial 方法。
所谓压栈也即是要记录这种调用的关系,以便当被调用方法返回时,能回到之前调用它的方法处继续执行。上图无法查看每次调用时 num 的值,要进入到 debug 的 perspective,
如果你用过 eclipse 来 debug 程序,你应该知道什么是 debug 的 perspective(我也不清楚这词要怎么翻译)。每次调用参数其实对应不同的值,比如第一次时 value 为 2:调戏程序是每个程序员的基本功!(如果你想带点广东式普通话的韵味,这样发音就对了~)

第二次调用时,value 已经是 1:

到了第三次调用,value 为 0,所以 if 条件才能满足,最终被断点捕获:

下面的一个图形像地展示了递归运行的情况,总共 6 个过程:(图片来自http://cg.scs.carleton.ca/~mathieu/COMP1006/notes/COMP1406_5/Recursion16.gif)
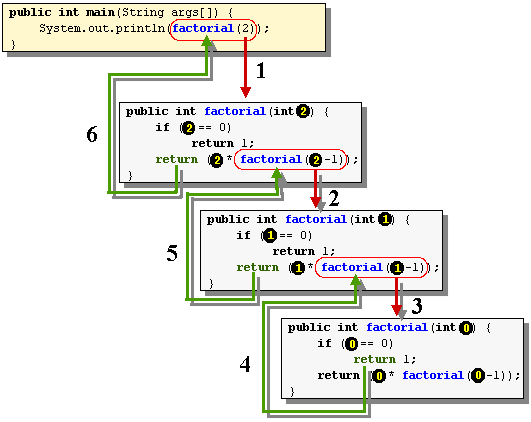{kind=link}
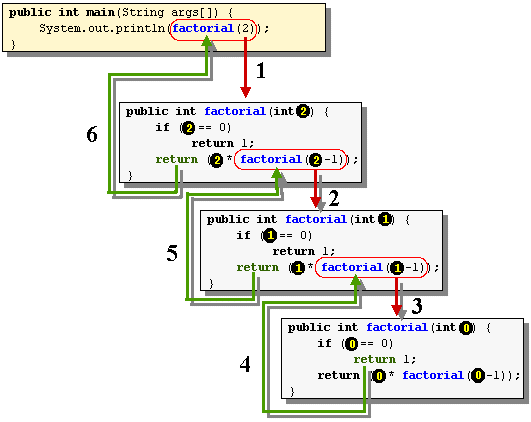
这个图实际就是个倒过来的栈。
方法的本地变量(local variable)
方法参数及其它在方法体内声明的变量都是方法的本地变量。main 中 args 以及 result 就是本地变量。前面说了,方法执行中如果调用了其它方法会导致当前方法被压栈,最终形成一个方法调用链:factorial 中的 num 也是本地变量。
所谓的栈也就是一个 FILO(first in,last out,先进后出)的队列。但这还不是问题的全部,栈中不单维护了方法间的调用关系,更重要的是保存了这些本地变量的值,它们被一同压到了栈中,以备在方法最终出栈时“恢复现场”。
试想有一个长长的方法,执行到一半时调用了其它方法,那么之前可能已经算出很多中间运算结果,保存在方法本地变量上,那么压栈时自然也要把这些结果保存起来。
调用实例与类的实例的对比
假如有个类 Person,可以视作是一个对象模板,new Person 可以产生许多彼此不同的实例(instance)
factorial 则是一个方法模板,当每发生一次压栈时,则可认为是生成了一个调用的实例放在那里:

如果把 factorial 想像成一个对象,用不同的参数调用时就好比 new 了一个个对象一样:
如 new factorial(2),new factorial(1), new factorial(0),所以,即便递归调用了自己,每次调用都是独立的。更重要的是,每个线程都会有自己的栈,彼此之间互不干扰。

所以,如果静态地去看代码,自己调用自己确实不好理解,但动态地去观察它的行为,那么,它调用自己与调用别人又有什么区别呢?
对电脑而言,无论是哪个方法都不过是一堆的指令,再次执行同一堆指令与转到另一堆指令上去执行其实没有任何区别。综上,有了栈这种结构,方法每次被调用时传入的参数及本地变量都能被捕获并维持,与 while 等循环反复修改一个变量不同,递归调用压栈时,每个变量都有自己的一份副本。
理解内存同样是程序员的基本功。有人揶揄 Java 说,“如果说 Java 中没有指针,那么空指针异常又是怎么来的呢?”如果你听说过 javascript 中的闭包(closure),那么你可能会发现那种机制与这里谈论的机制间有那么一点相似之处,如果不能从内存层面去思考变量的捕获与维持,那么去理解闭包这种抽象的概念将会是件困难的事。
菲波那契数列(Fibonacci sequence)
说完了阶乘,再说说菲波那契数列。定义相信大家都清楚了:简单讲就是前两项是 0 和 1,后面的每一项则都是它之前两项之和。具体如下:0 1 1 2 3 5 8 13 21 34 55 89 144…
由这些数字形成的螺线:

自然界的一些例子:

递归的表达优势
数学定义如下:
这一定义直接就可以翻译成代码:
public static int fib(int n) {
if (n < 2) {
return n;
} else {
return fib(n - 1) + fib(n - 2);
}
}
从中可以看出递归在表达能力上的优势,它没有for循环之类那种过于强烈的命令式,过程式的痕迹,整个表达显得简洁有力。
这里也体现了前面说的多个 recursive cases 的情况,这里面有两个 case:fib(n-1) 和 fib(n-2)。随着 case 的增多,乃至于参数的增多,用 for 之类的循环来表达将会越来越吃力。
递归的性能问题
当然,递归也不是没有缺点。就目前这个程序而言,有两个 case,以 fib(5) 为例,执行的展开是一种类似于树形的结构:
图片来自《计算机程序的构造和解释》(SICP:Structure and Interpretation of Computer Programs)书中截图。有一点很严重的就是存在巨大的重复计算的问题,正如上图的圈出的那样,在计算 fib(5) 时,fib(3) 被重复计算了两遍。
如果不考虑 fib(4) 中 fib(2) 的计算量,那么从 fib(4) 到 fib(5),计算量翻了一番,粗略估计它的计算量随着N的增长呈现指数式的增长。
按书中说法,fib(n) 就是最接近 φn/√5 的整数(φ 的 n 次方除以根号 5),其中 φ(phi)即是所谓的黄金分割(golden ratio),满足方程 φ2=φ+1,φ 的值约等于 1.618。有一种称为 memoization 的优化技术能够缓存计算的值,从而减少重复计算。
java 中应该没有这种优化,如果我们自己手动处理,大概就像是引入一个 hash map,存放着已经计算过的值。计算一个值之前先看看这里是否已经有结果了。当然,如果要自己显式去处理,整个代码就无法做到那么简洁了。
总结
有一种说法是:”计算机软件产业最为惊人的成就,是其持续不断地放弃硬件产业的惊人成果和稳定性。“撇去稳定性不谈,这里是在抱怨软件性能拖累了硬件的性能提升表现,用户电脑的硬件在不断升级,但用户还是觉得电脑很慢。“The most amazing achievement of the computer software industry is its continuing cancellation of the steady and staggering gains made by the computer hardware industry.”--Henry Petroski
当然,软件人这么任性一方面与水平有关,但另一方面,也存在这样的说法:
应该优化人的时间而不是机器的时间。其实语言的发展从早期的汇编语言到现在 javascript,python,ruby 等动态语言的兴盛,人们越来越强调的语言的表达能力。像汇编那样晦涩难懂的语言,即便性能很好,今天恐怕也没人愿意去用了。我们今天有丰富的软件可用,高级语言降低了编程的门槛自然也是功不可没。
最近有新闻说美国总统奥巴马都开始学编程了。因此,应该综合地去看待递归的优缺点。
关于经典的两个递归例子就分析到这里。