在讨论领域模型之前, 先继续说下关于测试方面的内容, 前面为了集中讨论相应主题而对此作了推迟, 下面先补上关于测试方面的.
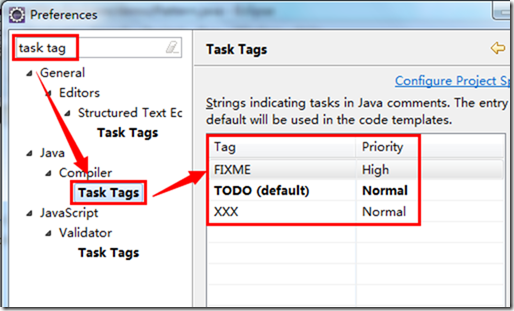
测试覆盖(Coverage)
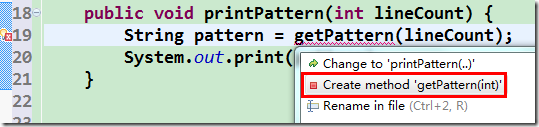
先回到之前的一些步骤上, 假设我们现在写好了 getPattern 方法, 而 getLineContent 还处于 TODO 状态, 如下:
public String getPattern(int lineCount) {
if (lineCount < 1) {
throw new IllegalArgumentException("行数不能小于1!");
}
if (lineCount > 20) {
throw new IllegalArgumentException("行数不能大于20!");
}
StringBuilder pattern = new StringBuilder();
for (int lineNumber = 0; lineNumber < lineCount; lineNumber++) {
pattern.append(getLineContent(lineCount, lineNumber));
}
return pattern.toString();
}
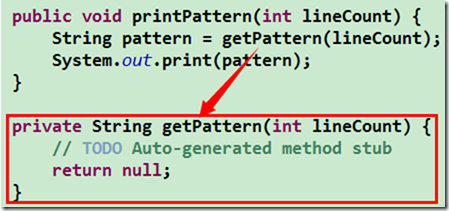
private String getLineContent(int lineCount, int lineNumber) {
// TODO Auto-generated method stub
return null;
}
显然, getPattern 已经是 OK 的了, 那么我们也应该为它写上一些测试了.
有人可能会想, 现在到底能测试什么? 毕竟它所调用的 getLineContent 还没有实现呢, 这里好像没有什么业务逻辑可测试的.
异常测试
但这里其实还是有些逻辑可测试的, 最明显的, 前面的两个前提条件, 它是否能如我们所愿拦住那些错误的参数呢? 对第一个条件让我们来测试一下:
@Test(expected = IllegalArgumentException.class)
public void testGetPatternSmallerThan1() {
Pattern p = new Pattern();
p.getPattern(0);
}
这里用了一个小于 1 的参数"0"去调用它, 并期待它能抛出相应的异常.
如果还想验证它的异常信息, 可以这样写:
@Test
public void testGetPatternBiggerThan20() {
Pattern p = new Pattern();
try {
p.getPattern(21);
// 如果没有抛出异常, 测试失败
fail();
} catch (Exception e) {
// 检查抛出异常的类型及信息
assertThat(e instanceof IllegalArgumentException).isTrue();
assertThat(e.getMessage()).isEqualTo("行数不能大于20!");
}
}
当然, 异常信息很简单, 就是从源码中拷贝过来而已. 可以让它带上所输入的参数, 这样提示更有意义, 从而也让我们的测试更有意义, 如下:
assertThat(e.getMessage()).isEqualTo("行数不能大于20!输入值: 21");
那么现在测试自然是不通过了, 可以再运行一次来确认. 那么现在再修改一下源码, 在抛出异常信息的地方改成:
public String getPattern(int lineCount) {
if (lineCount < 1) {
throw new IllegalArgumentException("行数不能小于1!输入值: " + lineCount);
}
if (lineCount > 20) {
throw new IllegalArgumentException("行数不能大于20!输入值: " + lineCount);
}
// ......
}
保存, 再运行测试, 如果这次通过了, 那么你基本可确认你已经实现了需求.
以上实践已经非常接近 测试驱动开发(TDD: Test Driven Development) 所倡导的方式:
- 根据需求先写一些测试, 而所测试的方法还没有实现这些需求, 因此这些测试还不能通过;
- 接着再写源码实现那些需求并让测试通过.
这就是所谓的测试驱动.
说完了异常方面的测试, 还有什么可测试的呢? 这里真的没有其它业务逻辑可测试了吗?
行为测试
没错, getLineContent 确实还是空的, 但不要纠结于这里, 比方说: 输入一个 3, 你调用了 4 次 getLineContent, 这不就错了吗? (可能的原因是在 for 循环部分的边界判断上没有写好)
那么怎么确切地去证明你的代码里只会不多不少只调用了 3 次呢? 可以借助 Mockito 中的行为测试来验证这些逻辑:
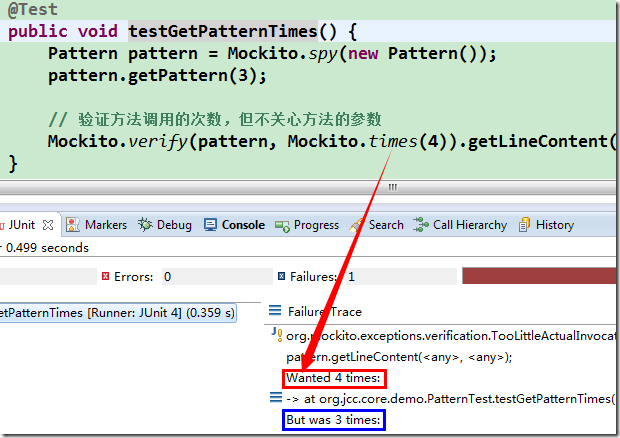
@Test
public void testGetPatternTimes() {
Pattern pattern = Mockito.spy(new Pattern());
pattern.getPattern(3);
// 验证方法调用的次数, 但不关心方法的参数
Mockito.verify(pattern, Mockito.times(3)).getLineContent(Mockito.anyInt(), Mockito.anyInt());
}
以上代码中, 用 Mockito 来构建了一个 pattern, 并调用了 getPattern 方法, 接着再断言 getLineContent 被调用了 3 次( Mockito.times(3) ).
至于用
Mockito.spy而不是用Mockito.mock, 原因是mock方式会让所有方法被覆盖, 除非显式使用when...then来指定方法的行为;而
spy则会保留原有方法的行为, 除非显式when...then来显式指定新的行为.现在我们想测试
getPattern方法, 所以用spy.
如果你对 Mockito 还不太熟悉, 也没关系, 你只要明白这里在验证方法调用的次数就够了. 可以改变一下, 比如改成 times(4), 再跑下就会发现以下错误提示:
另一方面, 你可能已经注意代码中的 Mockito.anyInt 方法, 你大概也能猜出这表示不考虑具体传递的参数是什么, 但传递的参数其实也是很重要的逻辑.
虽然在调用次数上正确了, 但如果没有传递正确的参数, 自然也不能算正确调用了方法. 让我们来验证这一点:
@Test
public void testGetPatternParam() {
Pattern pattern = Mockito.spy(new Pattern());
pattern.getPattern(3);
// 这里会验证方法调用的参数, 但并不会验证方法调用的顺序
Mockito.verify(pattern).getLineContent(3, 2);
// 等价于Mockito.verify(pattern, Mockito.times(1)).getLineContent(3, 2);
Mockito.verify(pattern).getLineContent(3, 0);
Mockito.verify(pattern).getLineContent(3, 1);
}
请注意, 我们这里假定行号从 0 开始, 这与之前的约定一致. 因此三次调用的参数分别是 (3,0),(3,1) 和 (3,2).
如果你再用一个 (3,3) 去验证呢? 显然, 代码中不会产生这样的调用, 因此将报错:
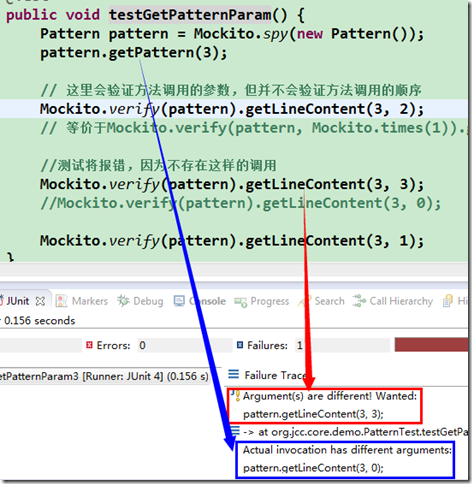
另外, 你可能还注意到了, 代码中先验证了 (3, 2), Mockito.verify 并不关心方法调用的顺序, 它只关注方法是否按照给定的参数被调用. 但方法调用的顺序自然也是逻辑正确与否的一个重要方面, 怎么去确保这一点呢?
因为 getPattern 方法有返回值, 我们正好可利用这一点:
@Test
public void testGetPatternOrder() {
Pattern pattern = Mockito.spy(new Pattern());
// getLineContent尚未实现, 我们先模拟它的行为
Mockito.when(pattern.getLineContent(3, 1)).thenReturn("world");
Mockito.when(pattern.getLineContent(3, 2)).thenReturn("!");
Mockito.when(pattern.getLineContent(3, 0)).thenReturn("hello ");
// 因为方法有返回值, 且由所调用方法的返回值顺序组装而成, 因此可以间接利用来验证调用的顺序
String content = pattern.getPattern(3);
assertThat(content).isEqualTo("hello world!");
}
这里体现了用 Mockito.spy 的好处, 一方面我们保留了 getPattern 方法的行为, 因为这是我们想测试的;
另一方面我们又可以去指定其它方法的行为, 比如 getLineContent 的行为.
需要注意的是, 指定 getLineContent 的行为必须在调用 getPattern 方法之前.
在上面的测试中, 我们用了一些比较随意的内容, 你当然可以模拟得更加正式一些, 如下:
@Test
public void testGetPattern() {
Pattern pattern = Mockito.spy(new Pattern());
// 可以模拟得很像, 但通常是没必要的. 因为在验证时的result也是由你来给出的.
// 对getPattern方法而言, getLineContent究竟返回什么并不重要
// 重要的getPattern是否以正确的顺序, 正确的参数去调用了getLineContent
Mockito.when(pattern.getLineContent(3, 0)).thenReturn(" *" + System.lineSeparator());
Mockito.when(pattern.getLineContent(3, 1)).thenReturn(" ***" + System.lineSeparator());
Mockito.when(pattern.getLineContent(3, 2)).thenReturn("*****" + System.lineSeparator());
String content = pattern.getPattern(3);
String result = " *" + System.lineSeparator()
+ " ***" + System.lineSeparator()
+ "*****" + System.lineSeparator();
assertThat(content).isEqualTo(result);
}
但正如注释中所说的那样, 在这里所进行的测试, 关注的其实是 getPattern 的逻辑. 在这一层面上, 我们假定 getLineContent 能正常工作, 然后考察依赖于它的 getPattern 方法的行为是否正确, 比方说是否以正确的参数进行了调用, 是否正确处理了返回的结果等等, 这些显然都是 getPattern 方法的职责.
如果我们通过 Mock 方式已经测试到了 getPattern 的方方面面, 理论上而言, 只要 getLineContent 正确了, 最终结果也会是正确的. 更重要的是, 当我们断言 getPattern 能正常工作时, 我们并不依赖于 getLineContent 的任何具体实现, 正如最开始时那样, getLineContent 甚至可以是尚未实现的.
关注点的分离(SoC: Separation of Concerts)
我们说前面的测试关注的是 getPattern 的逻辑, 而前提则是 getPattern 必须专注于自己的逻辑. 在代码中, 我们正是这么做的, 我们没有让 getPattern 方法大包大揽, 而是把生成每一行具体内容这一关注点分离到了 getLineContent 中, 从而让 getPatternt 专注于集成 getLineContent 返回的内容上.
SoC 是一种重要的设计原则, 你或许更常在 AOP(Aspect-Oriented Programming, 面向切面编程)的实践中听到所谓的 横切关注点(cross-cutting concerns), 也即所谓的切面了.
自然, AOP 也实践了 SoC 这一原则, 但 SoC 本身是一个更宽泛的原则, 你当然可以怀疑套用在这里是否有点牵强, 但我认为不必过于狭隘地去理解它.
单一职责原则(SRP: Single Responsibility Principle)
可以看到, getPattern 方法并没有过多的职责, 生成每一行具体内容的职责被委托到了 getLineContent 上. 正如我们前面用一个"hello world!"形式去验证那样, 具体返回什么那已经是 getLineContent 的职责了, getPattern 做好自己的事情就行了, 它不受其它变化的影响.
SRP 同样也是一种重要的设计原则, 你更常听到的可能是一个类或一个模块应该具有单一的职责. 在这里我们说的是方法, 你当然可以继续怀疑套用在这里是否有点牵强, 但我还是那句话, 不必过于狭隘地去理解它. 重要的是领会这些思想的精神实质, 你或许还能隐约感受它与 SoC 有点关系.
Robert C. Martin 把"职责"定义成"更改的原因"(reason to change), 认为一个类或一个模块应该有且只有一个更改的理由(a class or module should have one, and only one, reason to change.).
实际上, Mockito 不赞成使用 spy 方法, 它认为, 如果你要用 spy, 你的设计可能存在一些问题. 事实上, 如果增加一个叫 Line 的类, 并把 getLineContent 移到它的里面(或许名字还可改成更短的 getContent), 让 Pattern 类依赖于这一 Line 类, 那么就可以用 Mockito.mock 来构造 Line 的实例去测试 Pattern 类, 正像前面测试 PatternFile 与 Pattern 时那样, Pattern 类也能因此变得更加简单.
当然, 由于这是一个很小的例子, 你可以怀疑是否值得这么去做. 但在现实中, 如果你发现一个类正在不断膨胀, 你或许应该停下来好好想想它是否承担了过多的职责, 也许你已经到了一个值得拆分它的时间点.