
在前一篇章中已经谈了不少 Unicode 中的重要概念, 但仍还有一些概念没有提及, 一则不想一下说太多, 二则有些概念也无法三言两语就说清楚, 本文在此准备谈一下 代码单元 及由此引发的一些话题.
什么是代码单元? UTF-8, UTF-16 和 UTF-32中的 8, 16 和 32 究竟指什么?
代码单元指一种转换格式(UTF)中最小的一个分隔, 称为一个 代码单元(Code Unit), 因此, 一种转换格式只会包含 整数 个单元.
各种UTF编码方案下的代码单元
- UTF-8 的 8 指的就是最小为 8 位一个单元, 也即一字节为一个单元, UTF-8 可以包含一个单元, 二个单元, 三个单元及四个单元, 对应即是一, 二, 三及四字节.
- UTF-16 的 16 指的就是最小为 16 位一个单元, 也即两字节为一个单元, UTF-16 可以包含一个单元和两个单元, 对应即是两个字节和四个字节. 我们操作 UTF-16 时就是以它的一个单元为基本单位的.
- 同理, UTF-32 以 32 位一个单元, 它只包含这一种单元就够了, 它的一单元自然也就是四字节了.
所以, 现在我们清楚了:
UTF-X 中的数字 X 就是各自代码单元的位数.
你可能要问, Unicode 整出这么多的概念来做什么? 讨论代码单元这犊子有什么用? 下面我将会以 Java 为例来做些说明, 我们首先讨论一个非常普通的方法, string.length(), 你可能觉得自己已经完全理解了 length, 不就是字符串长度吗? 可是如果深入再问下这个长度究竟怎么来的, 它跟这里的代码单元有什么关系? 你可能就未必清楚了, 这里面的东西比你想像的要复杂.
注: 有些读者的语言背景可能并不是 Java, 但我想这里讨论的情况对于无论是哪种语言平台它都有一定的借鉴意义. 任何语言平台它去处理 Unicode 时都必然要面对类似的问题.
Java 中的 string.length 究竟指什么?
如果你阅读一下 java 中 String 类中的 length 方法的说明, 就会注意到以下文字:
Returns the length of this string. The length is equal to the number of Unicode code units in the string.
返回字符串的长度, 这一长度等于字符串中的 Unicode 代码单元的数目.
我们知道 Java 语言里 String 在内存中以是 UTF-16 方式编码的, 所以长度即是 UTF-16 的代码单元数目.
BMP 内的字符长度
通过前面的篇章我们知道, UTF-16 保存 BMP 中的字符时使用了两字节, 也即一个代码单元. 这就意味着, Java 中所有的 BMP 字符长度都是 1, 无论它是英文还是中文. 这一点我想大家都没有疑问. 代码示例如下:
@Test
public void testStringLength() {
String str = "hello你好";
assertThat(str.length()).isEqualTo(7);
}
这里我们用了 JUnit 的方式来测试, 如果你对此还不熟悉, 可以简单理解它是对使用 main 方法来测试的一种更好替代.
更多了解, 百度一下, 你就知道(抑或是谷歌一下, hope you are feeling lucky if you have no proxy(like VPN, goAgent, etc).
不出所料, "hello你好" 有 5 个英文字符加 2 个中文字符, 所以它的长度就是 7. 因此, 很多人就得出了一个结论: "string.length 就是 字符数". 但我们知道 UTF-16 同样可以表示增补平面中的字符, 而且用了四字节来表示, 也即 两个 代码单元. 如果 length 的 API 说明所言不虚的话, 那么, 一个增补平面中的字符, 它的长度将是 2!
增补平面中的字符长度
以前面反复提到的 U+1D11E 为例, 这是一个五位的码点, 用 UTF-8 编码需要四个字节, 用 UTF-16 需要一个代理对, 同样是四个字节才能表示. 这是一个音乐符 𝄞(MUSICAL SYMBOL G CLEF).
在你的电脑中可能无法正常显示这个字符, 因为没有相应的 字库 文件支持.
可参考网站上的显示 http://www.fileformat.info/info/unicode/char/1d11e/index.htm . 下图则是前面的一个截图:

下面的图是我在 Live Writer 上的截图, 可以看到如果选用默认的"微软雅黑"字体, 是无法正常显示的, 显示变成了一个白板. 为了显示它, 我只能对这个字符特别指定"Unifont Upper"字体它才能正常显示:
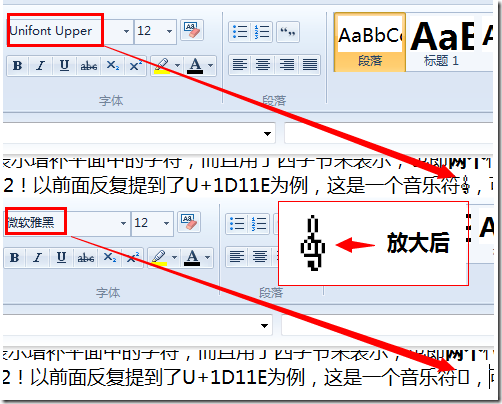
注: Unifont Upper 字体是我特别去下载的, 一般电脑上应该都没有这个字体. 微软有个"Arial Unicode MS", 但试了发现它还是只能支持 BMP 中的字符.
Unifont Upper 可以到以下网址下载http://www.unifoundry.com/unifont.html , 是免费的, 做的也比较粗糙, 大家看上图中放大的效果就知道了, 很明显是点阵字体, 而且似乎只提供了一种尺寸, 一放大就呈锯齿状了.
不过这是 GNU 号召一些志愿者为大家提供的, 大家都是无偿劳动, 有好过没有, 这点大家应该都能理解.
要想更好, 通常要矢量字体, 肯定有商业机构提供这些字体, 一切不过是钱的问题, 我想大家对此也是心知肚明. 有没有免费又好用的, 这个我就没有费心去找过了.
让我们来看看:
@Test
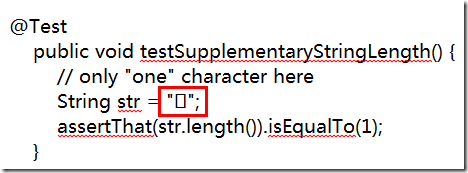
public void testSupplementaryStringLength() {
// only "one" character here
String str = "𝄞";
assertThat(str.length()).isEqualTo(2);
}
以上代码我已经发到 gitee.com 上, 见https://gitee.com/goldenshaw/java_code_complete/blob/master/jcc-core/src/test/java/org/jcc/core/encode/EncodingTest.java.
这是 Live Writer 源码插件中的情况, 发现编码已经丢失了, 变成了两个??.

而直接拷贝到 Live Writer 中, 虽然没法显示, 起码编码没有丢失, 还是一个字符, 跟前面类似:
如果特别调整一下这个字符的字体, 它还是可以显示的, 跟前面的道理一样.

我想, 这里就是一个个活生生的例子:
很多软件依然不能很好地支持 Unicode 中的增补字符, 甚至连编码也无法正确处理.
从源码插件输出两个问号, 我们可以猜测一下, 当拷贝发生时, 操作系统给了源码插件一段 UTF-16 编码的字节流, 其中有一个增补字符是以代理对形式表示的, 插件显然不能正确处理代理对, 把它当作了两个字符, 但单个代理对的编码都是保留的, 显然没有什么字符可以对应, 于是插件就用两个问号代替了.
以上仅是一种合理猜测, 因为没有深入了解 windows 中的拷贝机理及源码插件中的源代码, 真正的原因也许不是这样, 但可以肯定的一点就是它一定在某个环节出错了.
好了, 让我们直接看看代码运行的情况, 没法正常显示, 我们就截图来说明, 虽然免不了繁琐了些. 测试是通过了的, 一个增补字符它的长度确实变成了 2. 我给大家截个图, 这是大家电脑上可能显示出来的效果:
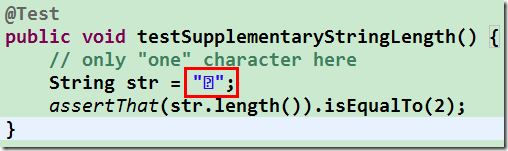
一个方框, 里面一个问号, 当字库里没有这个字时, eclipse 中就会以这样一个符号来表示, 这点跟 Live Writer 上显示一个白板又有所不同, 但原因是一样的.
为了显示这朵奇葩, 还是要设置 Unifont Upper 字体才行:
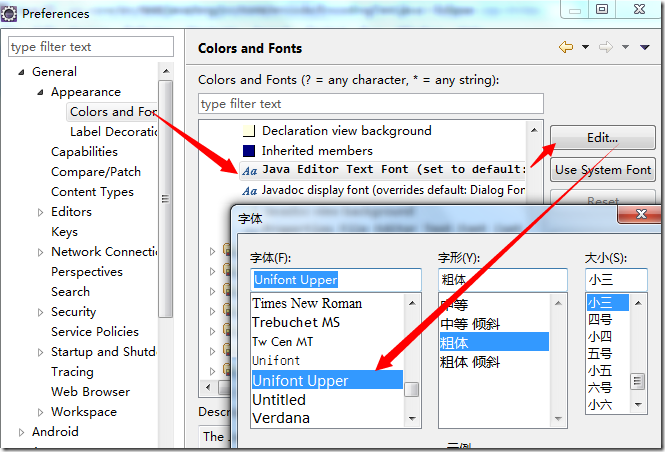
真是繁琐, 其实从前面图中两个引号紧密围住那个无法显示的字符也可以看出, 这里确实只有一个字符, 我没骗大家, 它的长度也的确变成了 2, 测试也通过了, 正如 API 中所说的以及我们分析的那样.
现在这一字符终于显示出它的真容来了. 现在把期望长度改一改, 把原来的 2 设置成 1, 再跑一下:
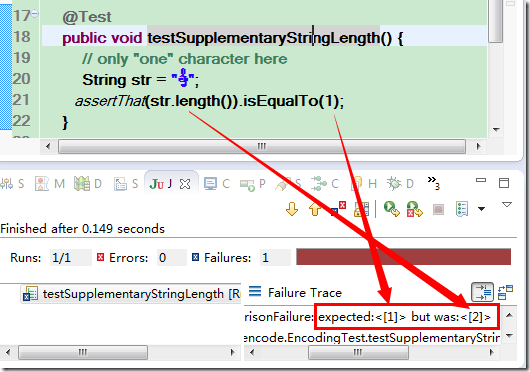
JUnit 华丽丽地报错了!它说期望的长度是 1, 但实际的却是 2!
注: 图中的 红条 可直观表示测试失败, 如果出现 绿条 则说明测试通过, 这是 JUnit 中的一个约定.
所以现在终于证实了 string.length 的 API 上所言不虚, 图上的 str 只有一个字符, 但它的长度却不是 1. 它返回的的确就是 UTF-16 的代码单元的数目, 而不是我们想像中的所谓"字符数".
以上是 Java 平台的情况, 不同的语言平台会有不同的情况, 这个需要具体问题具体分析. 特别的, 使用增补字符去测试能更容易揭示内部表示的实质.
既然已经到这步, 我们不妨多看几个例子.
char 类型与增补字符
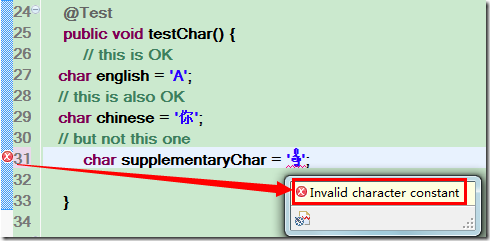
在上图中, 还试图把这个字符赋值给一个 char 变量, 发现编译器提示出错. 为什么呢? 因为 Java 中 char 使用了 16 位, 而这个字符在 16 位内已经无法表示, 所以它放不进一个 char 中.
可以看到, char 可以放一个英文字符, 一个中文字符, 那是因为这些字符都在 BMP 中, 但却无法放置这个音乐符, eclipse 的即时编译立马就报错了: "Invalid character constant"(非法的字符常量).
与此类似, 如果一个中文字符来自增补平面, 那么它也将无法放入 char 中.
另: 使用了这种非等宽字体后, 代码的对齐显示方面也出了问题, 缩进变得不统一.
增补字符的转义表示
另外我们可以以转义的代理对的方式表示这个音乐符号, 这样可以避免字库方面的问题.
当然了, 任何字符都可以用转义的方式表示, 而不仅仅限于增补字符. 如果你没有安装输入法, 可以简单使用 \u4F60 来表示"你"这个字符.
注: 如果担心传输中出现乱码, 可使用转义的表示, 这时只含有 ASCII 字符, 不过这种表示法效率很低.
比如我们要用 ", u, 4, F, 6, 0" 整整 6 个 ASCII 字符才能表示"你"这个汉字, 也即要用 6 字节才能表示.
而直接表示的话, 用 GBK 只要两字节, 而用 UTF-8 也不过是三字节.
从前面的篇章中, 我们知道 U+1D11E, 写成 UTF-16 的代理对是(D8 34 DD 1E).
Java 中的转义表示始终是以 \u 后接 四个 16 进制数字为界的(其实就是 UTF-16 的代码单元), 你不能简单像码点那样写成 \u1D11E, 这种写法相当于 "\u1D11"+"E", 即前面四位 1D11 做转义, 后面当成正常的字母 E.
如果要转义的字符码点超过 U+FFFF, 我们需要两个一对的转义 "\uD834\uDD1E" 来表示, 从这里我们也可看到, 所谓的转义表示其实就是 UTF-16 编码.
注: 以上是 Java 平台的情况, 不同语言平台可能有不同的策略.
新的 Javascript 版本(ES6)支持一种将码点直接放在大括号内的转义表示法"\u{1D11E}", 这显然要比写成代理对的形式简单, 也更直观.
我们可以用 "\uD834\uDD1E" 的转义方式表示 U+1D11E 这个码点所表示的字符, 只是这样的话, 不明就里的人可能认为这里有两个字符了, 所以输出 2 不奇怪.
这也正好从另一角度说明, 增补字符需要四个字节, 也即两个代码单元才能表示.
测试的代码如下: (注: 这是后面补上的, 所以跟下图有些差别, 没有重新截图)
@Test
public void testSupplementaryStringLengthUsingSurrogatePair() {
// only "one" character here, code point is U+1D11E
// 这里只有一个字符U+1D11E
String str = "𝄞";
// actually the same character, but represented by surrogate pair
// 同样的一个字符, 以转义的代理对方式表示
String anotherStr = "\uD834\uDD1E";
assertThat(str.length()).isEqualTo(2);
assertThat(anotherStr.length()).isEqualTo(2);
// these two equals each other
assertThat(anotherStr.equals(str)).isTrue();
assertThat(str.codePointAt(0)).isEqualTo(0x1D11E);
// not D834
assertThat(anotherStr.codePointAt(0)).isEqualTo(0x1D11E);
assertThat(anotherStr.codePointAt(1)).isEqualTo(0xDD1E);
}
在这里还让两个 string 进行了 equals 比较, 可以看到那条绿油油的成功指示条, 测试是通过的:
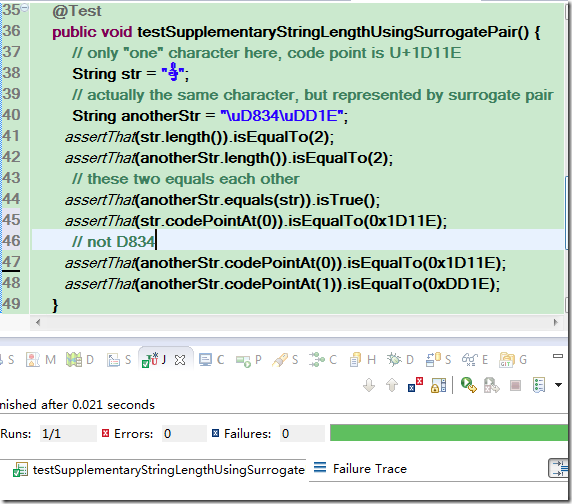
另外, 上图中还对两个 string 在 index=0 处的码点进行了求值(图中的 codePointAt() 方法), 可以看到无论是以字符表示的 str 还是以代理对表示的 anotherStr, 它们的码点都是 0x1D11E, 这也从另一个侧面证明了它们是同一个字符.
错误的代理对
如果反转了代理对, 会是什么情况呢? 前面篇章已经谈及, 代理对必须严格按照先高后低的顺序来书写, 以下代码中把代理对写反了:
@Test
public void 测试错误的代理对() {
String wrongPairStr = "\uDD1E\uD834";
assertThat(wrongPairStr.codePointAt(0)).isEqualTo(0xDD1E);
assertThat(wrongPairStr.codePointAt(1)).isEqualTo(0xD834);
System.out.println(wrongPairStr);
System.out.println("\uD834\uDD1E");
}
上面的测试, 方法名直接使用了中文, 其实 Java 中是可以支持这种命名方式的, 我们也免去了写完英文方法又要写中文注释的麻烦. 当然, 这样看上去可能让有些人觉得别扭.
让我们实际测试一下:
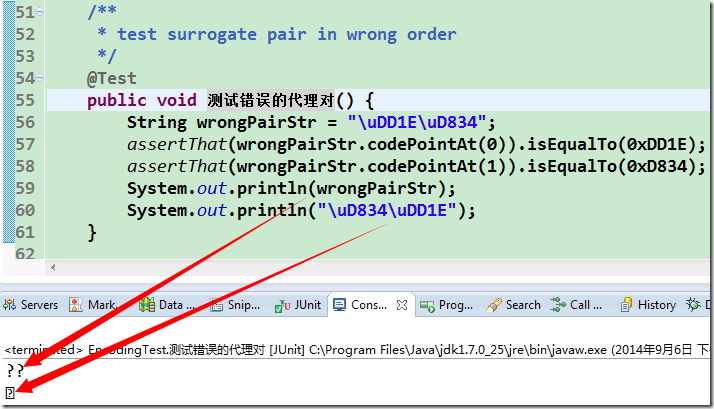
可以看到, 输出了两个问号, 在 index=0 处的码点也变成了 0xDD1E, 而不是原来的 0x1D11E 了, 而正常顺序则只输出一个字符. 再一次的由于字库原因, 它不能正常显示, 我也懒得去调整 console 的字体了, 大家明白怎么回事就行了.
结论
以上说了这么多, 不外乎就是为了证明一件事, java 中 string.length() 不是你想像中的那样. 在前面系列中的第三篇中, 我们就已经谈到变长的引入也同时带来了复杂性, 其中就说到了它影响到我们对 java 中的 string.length 的理解, 现在 length 显得有点尴尬, 如果我们真的想确切地知道有几个 字符, length 显然是不能给出正确答案的.
如果想要得到实际的长度, 也即代码点数量, 可以使用 codePointCount 方法:
@Test
public void testSupplementaryStringLength() {
// only "one" character here
String str = "𝄞";
assertThat(str.codePointCount(0, str.length())).isEqualTo(1);
}
目前来说, 增补字符使用得还比较少, 多数处理的还是 BMP 中的字符, 所以哪怕你没有认识清楚它的本质, 通常也不会给你带来什么麻烦. 但事情是在不断发展的, 也许不久的未来, 处理这些增补字符的问题就会成为常态.
比如说很多的那种表情符号往往就有不少是增补字符.
好了, 关于代码单元及 string.length 方法就分析到这里. String 中的许多方法跟编码问题紧密相关, 在下一篇中, 我们还将分析一下 string.getBytes() 方法并初步探讨一下乱码的问题.