
在前一篇的最后, 留下了一个问题, 即 string.getBytes("UTF-16") 会在开头多出两个字节 FEFF 来, Unicode 中称之为 BOM, 接下来就让我们一起来了解有关 BOM 的知识, 在此之前我们需要说说有关 端法 的知识.
什么是端法(endian)?
在具体介绍它之前, 让我们先看看鸡蛋的两种摆法:
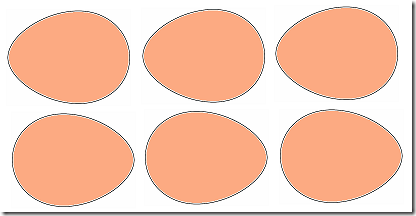
大家看出区别来了吗?
- 上面的一排都是尖的一端(或者说 小端)向着左, 较圆的一端(或者说 大端)向着右;
- 而下面一排正好相反.
画得不咋的, 大家凑合看就是了, 画出了<<蒙娜丽莎>>(Mona Lisa)的达芬奇(Leonardo da Vinci)据说开始学画画时也画过一段时间鸡蛋呢, 有说画了几天的, 也有说画了几年!
如果按照我们从左到右的习惯认为左是前面, 上面可以说是 小端在前, 而下面的则是 大端在前. 有人可能要问, 这与我们的 BOM 有何关系? 我们知道 UTF-16 一个代码单元有两个字节, 如果把一代码单元比作一个鸡蛋, 那么它也有两个端, 一个字节是小端, 另一个则是大端.
大端法(Big endian)
以两个 UTF-16 的编码 0x0048 与 0x4F60 为例, 如果我们把它们 书写 成 00 48 4F 60, 这样对我们而言也是非常自然的一种方式, 00 与 4F 都属于高位, 我们又常常说"高大高大"的, 高与大总是关系紧密, 自然这样一种高位在前的方式就是 大端法(Big endian) 了.
所谓的大端法, 就是大端在前, 上面图中下面一排的鸡蛋就是大端在前, 因此这种摆法也可以称为大端法.
那么, 自然的, 与大端法相反的那种就是小端法了.
小端法(Little endian)
还是以两个 UTF-16 的编码 0x0048 与 0x4F60 为例, 如果我们把它们 书写 成 48 00 60 4F, 那么这样一种低位在前的方式就是 小端法(Little endian) 了.
所谓的小端法, 就是小端在前, 上面图中上面一排的鸡蛋就是小端在前, 因此这种摆法也可以称为小端法.
我估计很多人会有些疑问, 为什么弄出这么一种很"不自然"很别扭的方式来呢? 请注意, 我给很不自然里的"不自然"三个字打了引号, 而且你可能也注意到了我在前面强调了 书写 两字, 其实呢, 大小端法应该是从 存储层面 考虑的, 在此之前让我们看看我们是如何看待内存布局的.
内存中的存储
如果有一排的格子来表示内存, 我们来给它们编号(其实就是 地址), 那么自然按照从左到右的习惯, 地址编号越来越大, 下面是一个四字节内存的示意图:

那么现在把大端法表示的四字节放进去, 结果如下:

那么我们发现, 就单个编码而言, 高位的字节反而放到了低地址上, 而低位的字节却放到了高地址上:
如上, 高位的字节 00 放到了低地址 0x0000 上, 低位的字节 48 却放到了高地址 0x0001 上. 4F60 的情况也与此类似.
这么下来, 我们所谓很"自然"的大端法反而有点不自然了.
与此相反, 让我们把小端法放入内存, 结果如下:

那么, 与大端法相反, 现在它的高低字节反而与地址的高低位自然地对应上了.
所以呢, 我们前面说小端"不自然", 那是对书写时的情况而言, 考虑到存储层面, 它看上去倒似乎更自然了.
需要强调的是, 所谓大小端仅仅是 字节间的关系,
这也暗示了只有 多字节 情况才会有所谓的端法, 而通常又在 偶数字节 情况下更为普遍, 如 UTF-16, UTF-32, 这样才能更好分出"两个端"来. 下面谈到 UTF-8 时将会再度阐述这一问题.
每个单独字节里的 8 个位依然还是高位在前, 无论大小端均是如此. 下图是小端法单个字节内部以二进制表示的示意图:

当然了, 建立在字节抽象层面上的操作已经无需关注字节内部究竟是什么端法了, 甚至已经不存在端法这一说法了.
大小端法的来历
关于 Big endian 和 Little endian, 它们是有来头的, 下面文字引自阮一峰的网络日志http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
这两个古怪的名称来自英国作家斯威夫特的<<格列佛游记>>. 在该书中, 小人国里爆发了内战, 战争起因是人们争论, 吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开. 为了这件事情, 前后爆发了六次战争, 一个皇帝送了命, 另一个皇帝丢了王位.
所以你明白了为何前面先画了几个鸡蛋来示意. 我们当然不会无聊到为鸡蛋从哪头敲开去打仗, 不过关于端法哪种好也是争论不休的, 在前面我们就谈到了哪种更"自然"的问题.
端法与系统架构
在 Windows 平台下, 当使用记事本程序保存文件时, 编码里有几个选项:
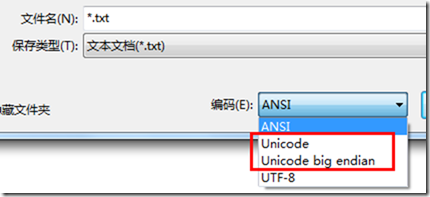
可以看到一个 Unicode 和 Unicode big endian, 通过以上名称的对比及对大端法的特别标示, 我们可以猜测出, Windows 下缺省是小端法.
注: 关于这里的 Unicode, 前面篇章中也有提及, 实际就是 UTF-16 编码.
Windows 平台为何使用小端法呢? 说起来与 CPU 制造商 英特尔(Intel) 又有很大关系.
这两者我们又常叫它们为 Wintel 联盟. (Wintel=Windows+Intel)
内存(Memory) 中使用端法其实又是受到 寄存器(Register) 中使用的端法的影响, 因为两者之间经常要来回拷贝数据. 英特尔的 CPU 就使用了小端法.
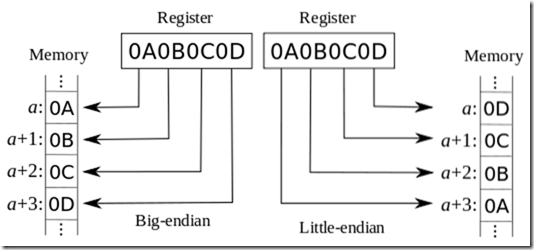
需要强调的另一点是, 虽然我们讨论是字符集编码, 但端法并不限于此, 还可以是其它, 比如一个 int, 通常是 4 字节, 以一个整数 0x0A0B0C0D 为例(以下图片来自 wiki 的截图):
除此之外, 图片文件中也可能会涉及端法的问题, 网络传输中也同样有端法的问题, 对此有兴趣的可以参考http://en.wikipedia.org/wiki/Endianness.
至于为何英特尔采用了小端法, 而其它一些厂商又使用了大端法以及这两种端法到底哪种好等问题, 这里就不打算深入下去了, 总之, 大家知道这个世界比较乱就是了, 有兴趣有精力的同学可以自行搜索以了解更多.
在 2010 年央视春晚小品<<捐助>>中, 赵本山的徒弟王小利扮演的亲家说: 他刨得不深, 我要往祖坟上刨. 针对端法的争论, 这里就不打算往祖坟上刨了, 另一方面的原因是刨不动了, 再刨就到硬件层面上去了, 所以呢, 非不为也, 是不能也!
回到编码的问题, 在记事本中以 ANSI 之外的三种编码分别保存一下 "hello你好", 分别命名为:
- UTF16BE.txt(对应 Unicode big endian)
- UTF16.txt(对应 Unicode)
- UTF8.txt(对应 UTF-8)
再以16进制查看一下:
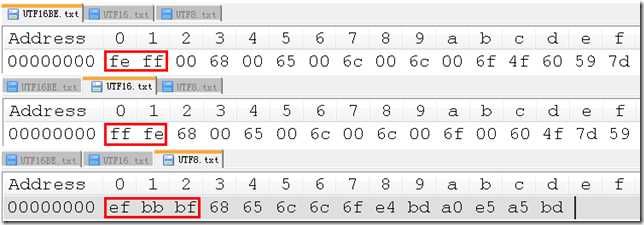
什么是 BOM?
BOM=Byte Order Mark, 翻译过来就是 字节顺序标识, 也即是上图中红色框中的部分.
自然地, 这里所谓的字节顺序其实就是指使用了哪种端法.
从上图中可以看出:
- UTF-16 BE(Big Endian)的 BOM 是: FE FF
- UTF-16 LE(Little Endian)的 BOM 是: FF FE
- UTF-8 的 BOM 是: EF BB BF
注: 前面说到,
getBytes("UTF-16")得到的缺省 BOM 是 FEFF, 可见 JVM 中缺省是大端法, 这与 Windows 平台下缺省为小端法恰好相反.
UTF-32 的 BOM
虽然前面一直在说的是 UTF-16, 但 UTF-32 同样也有 BOM, 以下代码是一些测试:
package org.jcc.core.encode;
import java.io.UnsupportedEncodingException;
import org.junit.Test;
import static javax.xml.bind.DatatypeConverter.printHexBinary;
import static org.assertj.core.api.Assertions.assertThat;
public class BOMTest {
@Test
public void testBOM() throws UnsupportedEncodingException {
String s = "hello你好";
// ============================ UTF-16
// java中的缺省是大端
assertThat(printHexBinary(s.getBytes("UTF-16"))).isEqualTo("FEFF00680065006C006C006F4F60597D");
// 注意: 特别指明端法后的字节数组将不再带上BOM
assertThat(printHexBinary(s.getBytes("UTF-16BE"))).isEqualTo("00680065006C006C006F4F60597D");
// 小端法表示的字节数组需要特别使用"UTF-16LE"来获取
assertThat(printHexBinary(s.getBytes("UTF-16LE"))).isEqualTo("680065006C006C006F00604F7D59");
// ============================ UTF-8
// java中, UTF-8缺省不带BOM, 这点与记事本又不同
// 另: UTF-8不存在所谓的大小端, 全部是大端, BOM仅仅作为一种所用编码的指示
assertThat(printHexBinary(s.getBytes("UTF-8"))).isEqualTo("68656C6C6FE4BDA0E5A5BD");
// ============================ UTF-32
// UTF-32太长, 用短一点的串来测试
String s32 = "he";
// 注意: 在本机测试时, 缺省情况下也没有BOM(不同的虚拟机实现可能会不一样!!)
assertThat(printHexBinary(s32.getBytes("UTF-32"))).isEqualTo("0000006800000065");
// 为防止意外, 最好明确设置
assertThat(printHexBinary(s32.getBytes("UTF-32BE"))).isEqualTo("0000006800000065");
assertThat(printHexBinary(s32.getBytes("UTF-32LE"))).isEqualTo("6800000065000000");
}
}
不过, 有点遗憾的是, UTF-32 在本机测试时, 缺省情况下也没有 BOM 输出, 这点与 UTF-16 的情况又不同:
但以上仅是在本机测试的情况, 请不要将此作为一个结论, 不同的虚拟机实现可能会不一样!!
下图是各种 BOM 的一个汇总(图片截取自 unicode.org):
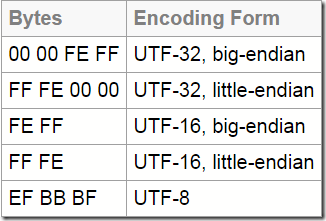
BOM 与码点 U+FEFF
BOM 其实就是 U+FEFF 这一码点, EF BB BF 就是这一码点在 UTF-8 下的编码. 代码如下:
@Test
public void testBomCodePoint() throws UnsupportedEncodingException {
String s = "\uFEFF";
assertThat(printHexBinary(s.getBytes("UTF-8"))).isEqualTo("EFBBBF");
}
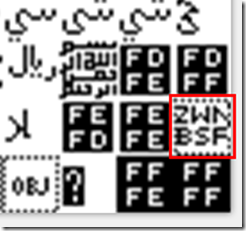
U+FEFF 称为 zero-width non-breaking space
字面义: 零宽度非换行空格. 也即碰到时把它解释成这样, 显示上的实际效果就是啥也没显示.
缩写成 ZWNBSP, 如下图所示:
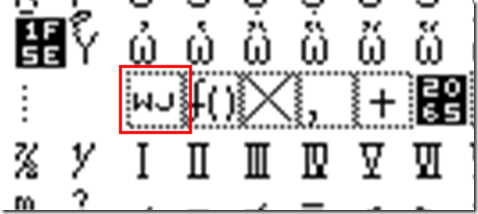
在用作 BOM 之后, Unicode 不再建议这样去解释(deprecated), 而是建议用 U+2060 来代替, U+FEFF 就作为 BOM 的专用.
U+2060 称为 Word Joiner(词连接器), 缩写为 WJ, 如下图所示:
UTF-8 的 BOM
从前面测试可知, java 中, UTF-8 缺省不带 BOM, 这点与记事本又不同:
按 Unicode 组织的说法, UTF-8 可带可不带 BOM, 不作强制要求, 但不推荐用 BOM, 原因之一是为与 ASCII 的兼容.
另: UTF-8 也不存在所谓的大小端两种情况, 统一为大端法, BOM 仅仅作为一种所用编码的指示.
UTF-8 中有一字节的情况, 这种情况, 就没有两端的说法了. 至于另外的二, 三, 四字节情况, 以三字节为例, 如果你一定要弄出端法, 也不是说不可以, 比如, 小端法就是"小-中-大", 大端法就是"大-中-小".
但现实情况是 UTF-8 仅仅采用了一种端法, 就是大端法.
UTF-8 中的 BOM 已经偏离了它的本意, 而这一点估计也是 Unicode 组织不推荐在UTF-8 中使用 BOM 的一大原因.
在 eclipse 中, 以 UTF-8 保存时就没有 BOM, 但它的编辑器也能正确处理带 BOM 的情况. (这个世界还真有点乱~)
总结
其实关于端法及 BOM 并没有太多好说的, 通常大家知道有这么一回事或者说有那么一些"坑"也就够了, 关于 BOM 的话题就谈到这里.