
先讲个小故事, 虽然跟主题有点不太相关哈:
唐朝诗人李绅, 身为官员, 脾气暴躁, 瞧不起信教的, 尤其鄙视装逼之僧人, 动不动就对他们拳脚相加. 曾扬言: "我可以接见他们, 要能答出来还好, 要是答不出来, 我弄死他!" 有一回一个和尚来跟他宣传因果报应, 李绅问: "阿师从哪里来, 到哪里去呢?" 僧答: "贫僧从来处来, 到去处去." 李绅当时就急了, 撸起袖子, 亮出了手腕: "我去年买了个表!"
来自知乎问答"古人是如何「装逼」的? ", 略有改动.
String 到哪里去?
有了前面僧人的教训, 在这里就不故弄玄虚了, 应该说 String 的去处还是蛮确定的, 那就是到 byte[] 中去, 方式就是通过 getBytes 这一方法.
new String 与 getBytes
如果说 new String(byte[], encoding) 是从 byte[] 到 String 的过程, 那么 getBytes(encoding) 则正好与之相反: 它是从 String 到 byte[] 的过程.
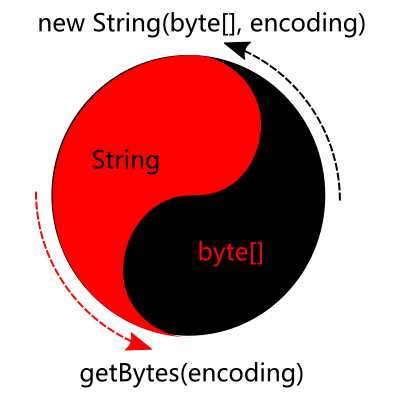
或许我们应该说: 它从去处来, 又到来处去.
编码的逆转
显然, 我们一直在说, String 也不过是一堆 byte, getBytes 的过程不过是 UTF-16 编码的 byte[] 再转回去其它编码的 byte[] 的过程.
无论是 new String 还是 getBytes, 不过都是在玩编码的转换而已.
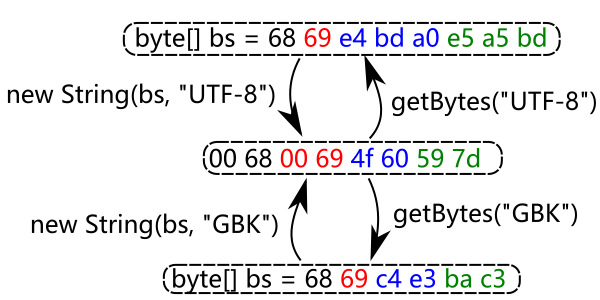
从上图中可以看出 String 作为桥梁, 可以把一种编码的字节转换成另一种编码的字节. 比如把一串的 UTF-8 编码的字节转换成 GBK 编码的字节的.

String 作为转换中的一方, 它的编码始终是确定的, 也即是 UTF-16;而 encoding 参数始终指的是 byte[] 的编码:
或者用于指明源字节的编码(new String 时);
或者用于表明希望转成何种编码的目标字节(getBytes 时).
具体转换过程
以 GBK 为例, 既然前面说, GBK 转 UTF-16 可以通过查表实现:
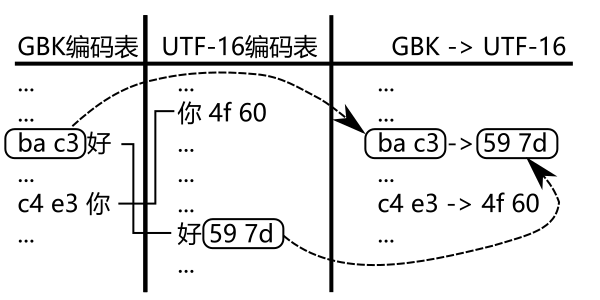
那么 UTF-16 转 GBK, 我们只需要反查那张表即可. 当然, 考虑到效率的问题, 我们可能需要另一张按 UTF-16 编码排序的表:
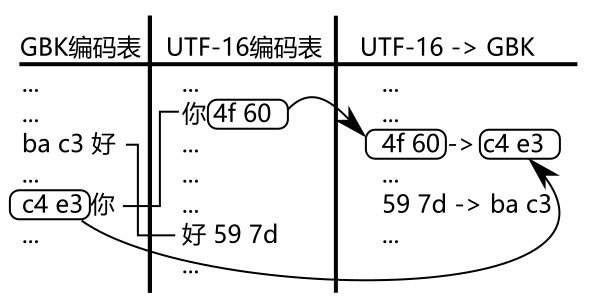
当然了, 这些都不需要我们去操心的.
至于 UTF-16 转成 UTF-8, 依旧可以通过码点这一桥梁来进行.
这里就不再演示了, 与前面码点转 UTF-8 非常类似:

剩下的如转 ISO_8859_1 以及 ASCII 之类的, 那就更简单了. 如果一段 String 表示的是 ISO_8859_1 或者 ASCII 中的字符, 显然里面每个 char 的高位都是 00, 因此只要把这些没用的 00 掐掉就行了.
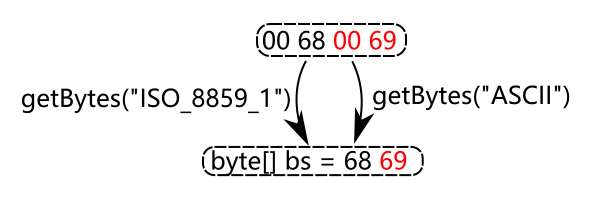
如果调用 getBytes("UTF-16") 呢? 那就不存在转换了, 相当于复制了一遍, 不过要注意它会带上 BOM, 除非明确指明了端序.

如果调用 getBytes("UTF-16BE"), 那么内存中就会出现两组一模一样的字节了.

但是这两者还是有本质的区别的, 原因就在于指向这两者的引用所代表的类型的不同.
类型赋予了一串 byte 丰富的内涵, 决定了我们怎么去解释它.
String 是一种有趣得多的类型, 它有明确的编码, 还有丰富多样的方法与之绑定. 而另一方面, byte[] 则要原始单调乏味得多. 严格地说, byte[] 只是一堆字节而已, 就编码这个问题而言, 它本身没有与任何编码绑定.
当然, 字节间的特征也许能让你断言这不是某种编码, 但你却不能肯定地说, 一串字节一定是某种编码.
多种解释
我们来看个具体例子, 还是拿前面说到的那串 GBK 编码的 byte 来说吧: 68 69 c4 e3 ba c3.
之所以说它是 GBK, 那是因为我们用 GBK 编码保存文件得到的它. 但如果内存中有一段与之一模一样的 byte[], 难道你能说它一定是 GBK 编码吗?
首先可以确定它不可能是 ASCII, 因为有些字节最高位是1, 那么它有可能是 ISO_8859_1 吗? 这是有可能的. 而对它的不同解释会因此在内存中生成不一样的 String:
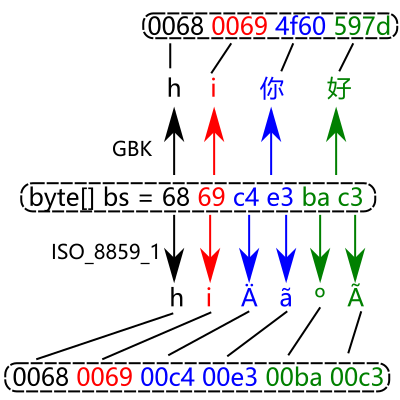
具体的代码测试也可以反映这一点:
@Test
public void testReadGBKBytesAsISO_8859_1() throws Exception {
File gbk_demo = FileUtils.toFile(getClass().getResource("/encoding/gbk_demo.txt"));
// 当成ISO_8859_1来读取
String content = FileUtils.readFileToString(gbk_demo, "ISO_8859_1");
assertThat(content).isEqualTo("hiÄãºÃ");
assertThat(content.length()).isEqualTo(6);
}
有的时候, 你没有办法拿到最底层的 byte[], 你直接收到的就是一个 String, 而这个 String 是通过错误的编码构建的, 如下所示:

第一步不受我们控制, 这时有一种 hack 的方式, 也即是通过上面的第二步再度拿回原始的 byte[], 再通过第三步传入正确的编码再度构建出 String. 代码演示如下:
@Test
public void testISO_8859_1Hack() throws Exception {
File gbk_demo = FileUtils.toFile(getClass().getResource("/encoding/gbk_demo.txt"));
// 当成 ISO_8859_1 来读取
String content = FileUtils.readFileToString(gbk_demo, "ISO_8859_1");
assertThat(content).isEqualTo("hiÄãºÃ");
assertThat(content.length()).isEqualTo(6);
// 再次拿到原始 byte[], 并以新的编码重新构建 String
content = new String(content.getBytes("ISO_8859_1"), "GBK");
assertThat(content).isEqualTo("hi你好");
assertThat(content.length()).isEqualTo(4);
}
当然, 我们并不鼓励这样繁琐地转来转去, 正确的姿势应该是这样的:

通过修改配置, 就能一步到位得到正确的 String, 不需要曲线救国.
有人可能说, 我并没配置过 iso_8859_1 呀, 那么这可能是某种缺省编码.
总之, 如果你收到被疑似 iso_8859_1 错误编码的 String, 那肯定是某个环节使用了这一编码.
当然, 如果你工作在一个遗留系统上, 还是要非常慎重地去改变这些缺省的编码配置, 因为可能严重冲击到那些依赖于这些缺省设置的代码.
比如上述 hack 方式可能就失效了, 而你可能不知道系统到底有多少地方使用了这种 hack.
关于 String 到哪里去的问题, 就探讨到这里.