
Java 的 IO 系统是比较庞杂的, 各种流特别多, 其中有一种就是字符流.
在本系列前面的一些文章中, 也曾涉及过字符流的话题, 不过没有详细展开讨论, 这次准备具体综合地谈一谈.
在层次方面的对比
你可能听过不少关于字节流与字符流对比的介绍, 不过严格地说, 我认为把"字节流"和"字符流"去对比这种说法不是特别妥当, 为什么呢?
首先, 这两种流实际上处在不同的层次, 字节流是基础, 而字符流是构建在其上的:

对于不同层次上的事物, 我认为用"对比"这个词是不太恰当的.
Java 的 IO 系统是比较庞杂的, 各种流特别多, 其中有一种就是字符流.
在本系列前面的一些文章中, 也曾涉及过字符流的话题, 不过没有详细展开讨论, 这次准备具体综合地谈一谈.
你可能听过不少关于字节流与字符流对比的介绍, 不过严格地说, 我认为把"字节流"和"字符流"去对比这种说法不是特别妥当, 为什么呢?
首先, 这两种流实际上处在不同的层次, 字节流是基础, 而字符流是构建在其上的:
对于不同层次上的事物, 我认为用"对比"这个词是不太恰当的.
深入探讨了缺省情况下浏览器的响应行为, 包括静态和动态的响应, 最后, 对所有情况作了一个简单总结.
在上一篇我们谈论了 BOM 编码的页面, 并知道了它是有最高优先级的. 而这一篇将讨论最后的一个主题, 也就是缺省的情况. 既然名为缺省, 也就不难想到, 它的优先级是最低的, 也即是在其它情况下都无法确定编码时, 才轮到它上场.
前面说到, 缺省就是没有 BOM, 响应头中的 Content-Type 也没有 charset 声明, 文档内也没有 meta charset 的声明, 这时浏览器该如何确定 html 页面的编码呢? 这里将设计一系列实验以探究这个问题.
首先是构建一个缺省的响应. 比如去构建一个 gbk 编码的文档, 自然就没有所谓的 BOM 了;然后用 gbk 编码保存这个文档, 但在文档内也不声明;之后配置服务器的响应头也不带 charset 信息. 这样一来, 浏览器收到这个文档流时无法获得任何有效的编码信息, 就将进入缺省的处理模式.
构建一个缺省的 gbk 文档时有几点要注意. 这点在前面的"文档内编码声明"章节也已经提到过, 特别是你在一个工程缺省编码为 UTF-8 的项目内创建这样的文档时更要注意, 当你删掉 meta charset="gbk" 的声明时, 智能的 IDE 编辑器可能会悄悄调整所使用的编码.
最好是在外部用记事本或 notepad++ 这样的通用文本编辑器来创建一个缺省的 gbk 编码的文档.
深入介绍了 html 页面使用 BOM 编码的情况, 它的优先级为什么最高以及具体的静态页面和动态响应的测试示例.
这一篇将介绍 BOM 在 html 页面编码中的运用. 在最前面曾提到, 它的优先级实际上是最高的, 在这里, 将具体介绍什么是 BOM, 还会解析为什么它的优先级最高, 然后还会构建一些具体的测试来验证这一点.
关于什么是 BOM, 在这篇文章中有详细的介绍:
这里也稍微啰嗦几句, 内容也基本出自上述文章: BOM=Byte Order Mark, 翻译过来就是"字节顺序标识".
具体则分为两种: 小端序(Little endian) 和 大端序(Big endian).
我们知道, 在记事本中 "另存为" 时可以选择编码, 有以下几种:
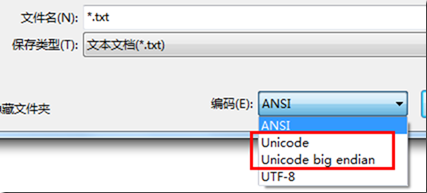
这里的 Unicode 实际就是 UTF-16(小端序).
注: Java 平台中 UTF-16 缺省为 大端序, 与 Windows 恰好相反.
另: 记事本的 UTF-8 默认是带 BOM 的, 而多数 IDE 的编辑器 UTF-8 默认不带 BOM.
深入介绍了响应头 Response Headers 中的 Content-Type 中的 charset 信息的应用, 包括许多在静态文档和动态文档中的实验与测试的细节, 以及一些具体配置和与文档内编码声明的优先级问题.
在上一篇说完了如何 通过文档内的编码声明来确定网页的编码 通过文档内的编码声明来确定网页的编码, 这一篇则开始具体讲述如何通过响应头下的 Content-Type 条目中的 charset 信息来确定文档的编码, 包括如何去配置这个响应头, 以及一些具体的实验, 还有它与文档内编码声明的优先级选择问题.
通过前面的介绍, 你已经知道了所谓的"响应头下的 Content-Type 条目中的 charset 信息", 就是这样:
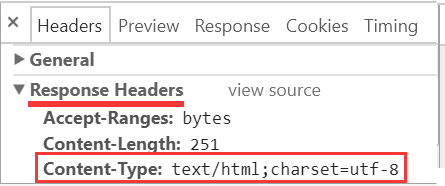
或这样的东西:
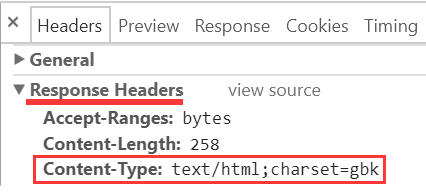
它指出了这段响应流的编码.
深入介绍了文档内编码声明的应用, 包括许多在静态文档和动态文档中的实验与测试的细节, 以及其它的一些注意事项等.
接着 上一篇中的讨论, 也是先从"文档内编码声明"讲起, 因为它是最直观也最容易控制的.
不过事实上也没有那么容易, 它还是很容易受各种因素干扰, 下面会详细介绍整个过程, 囊括了静态文档响应和动态文档响应两种情况, 以及各种其它注意事项.
通过之前的介绍, 你已经知道了所谓的文档内 meta charset 声明:
<meta charset="gbk">
以上为 html5 的标准写法. 又或者这样(html4)
<meta http-equiv="Content-Type" content="text/html; charset=gbk">