
<<编码: 隐匿在计算机软硬件背后的语言>>一书中的示例电路的线上可交互示例.

点此链接: https://book.xiaogd.net/code-hlchs-examples/code-hlchs-circuit-list.html
<<编码: 隐匿在计算机软硬件背后的语言>>一书中的示例电路的线上可交互示例.
点此链接: https://book.xiaogd.net/code-hlchs-examples/code-hlchs-circuit-list.html
探讨了表单以 post 方式, enctype 为 multipart/form-data 提交时数据所使用的字符集编码(包含缺省使用页面编码及设置了 accept-charset 时两种情形), 包括了上传文件及使用中文文件名时的情况, 以及后台的接收处理.
在上一篇中提到, post 方式按 enctype 的不同, 分成两种情况, 一种是 application/x-www-form-urlencoded, 前面已经分析过了, 这一篇则讨论剩下的那种: multipart/form-data.
虽然在很多的情况下, 都可以使用缺省的 application/x-www-form-urlencoded 方式, 但它是有缺点的, 比如它编码的效率不高, 因为它采用了低效的转义表示法.
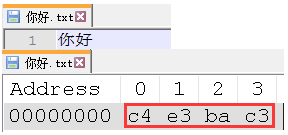
举个例子来说, "你好" 两字用 gbk 编码只需要 4 个字节: C4 E3 BA C3. 如下:
而如果表示成转义的形式呢? 是这样的 %C4%E3%BA%C3, 这一串整整有 12 个 ASCII 字符, 一个 ASCII 字符就要用一个字节来表示, 所以转义形式需要 12 字节, 是非转义形式的三倍:

可以看到光是百分号(%, ASCII 为 0x25)本身就占了 4 个字节了.
另外的情况是, 有时表单上还有上传文件的需求, 这时候 HTML 规范要求只能使用 multipart/form-data 形式.
探讨了表单以 post 方式, enctype 为 application/x-www-form-urlencoded 提交时数据所使用的字符集编码, 具体介绍了缺省情况以及设置了 accept-charset 属性时的情况, 同时介绍了后台在取出表单数据前如何使用 setCharacterEncoding 来设置正确的解码.
在上一篇章中谈论了表单以 get 提交时的编码与乱码问题, 这一章中将讨论以 post 方式提交时的编码与乱码问题.
在前面也同时提到, 表单有一个叫 enctype 的属性, 它有两个值, application/x-www-form-urlencoded 和 multipart/form-data.
这一属性实际只对 post 方式起作用, 因为 get 方式实际只支持前一种类型, 也就是 application/x-www-form-urlencoded, 这是缺省的类型.
在使用 post 方式提交时, 缺省的编码类型也依然是这个 application/x-www-form-urlencoded. 在这一篇章中, 先讨论这一类型;在下篇中, 再讨论 multipart/form-data 类型.
探讨了表单以 get 方式提交时数据所使用的字符集编码, 具体介绍了缺省情况, 此时使用文档本身的编码;以及设置了 accept-charset 属性时的情况.
深入介绍了 URL 中的转义编码, 用具体例子讲解了不同页面编码的情况下, 查询字符串转义时所使用的编码, 还顺带对 url 的组成结构作了介绍.
在上篇中, 初步谈论了 URL 中含有中文字符时的转义编码, 提到了所使用的编码是 utf-8.
不过你可能会有点疑问, 一定都是要用 utf-8 编码吗? 还是因为页面编码本身是 utf-8 的缘故呢? 毕竟在那个例子中, 页面的编码也恰好是 utf-8.
这次, 将继续测试页面编码是 gbk 时的情况, 如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="GBK">
<title>带中文的 URL(GBK)</title>
</head>
<body>
测试带中文的 URL,页面编码为:GBK
<br> 中文链接:
<a href="你好/index.html">你好/index.html</a>
<br> 中文链接并带有中文查询字符串:
<a href="你好/index.html?s=你好">你好/index.html?s=你好</a>
</body>
</html>