
前面的一些篇章更多谈论了 Unicode 的相关话题, 虽然也有提到 GBK 等编码, 但都没细说, 这里打算系统说一下. GB 系列包括 GB2312, GBK, GB18030.
前面已经提过, GB=Guo Biao=国标=国家标准, 至于所谓的 2312 就是一编号了, 没有其它特别的意义, 18030 类似.
GBK 没有编号, 所以它实际上并不是国家标准, 只是一个事实标准, GBK 中 K 指 扩展 的意思.
最早的是 GB2312, 我们从它开始说起.
摘要: 关于 GB2312, GBK, GB18030 编码的一些介绍, 还有区位码, 国标码, 机内码间的转换关系.
前面的一些篇章更多谈论了 Unicode 的相关话题, 虽然也有提到 GBK 等编码, 但都没细说, 这里打算系统说一下. GB 系列包括 GB2312, GBK, GB18030.
前面已经提过, GB=Guo Biao=国标=国家标准, 至于所谓的 2312 就是一编号了, 没有其它特别的意义, 18030 类似.
GBK 没有编号, 所以它实际上并不是国家标准, 只是一个事实标准, GBK 中 K 指 扩展 的意思.
最早的是 GB2312, 我们从它开始说起.
摘要: 简单介绍了 ASCII 和 ISO-8859-1 两个常见的字符集(编码).
在前面其实也谈到了 ASCII 了, 但并没有很具体, 作为一个完整系列的一部分, 还是有必要谈一下, 也作为后面讨论的一些基础.
它的全称是 American Standard Code for Information Interchange(美国信息交换标准代码), 是一个 7 位字符编码方案. 下面是它的一张简图(来自http://www.asciitable.com/index/asciifull.gif):
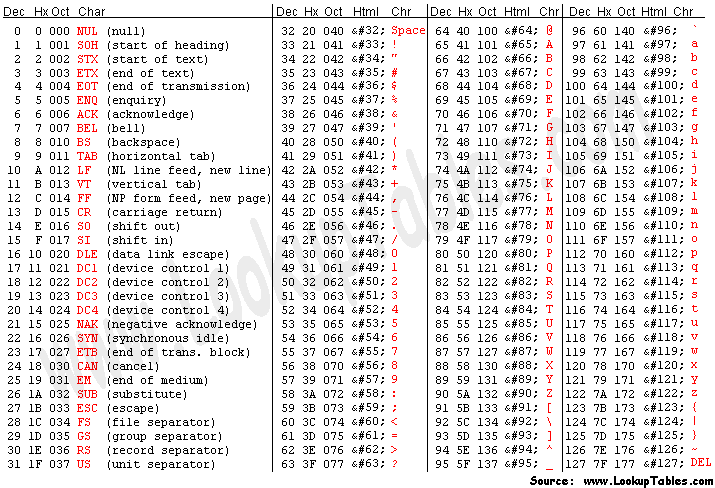
ASCII 定义了 128 个字符, 包括 33 个不可打印的 控制字符(non-printing control characters) 和 95 个可打印的字符.
摘要: 本文讨论了 Unicode 中的 BOM 及与 BOM 紧密相关的端法(endian)问题.
在前一篇的最后, 留下了一个问题, 即 string.getBytes("UTF-16") 会在开头多出两个字节 FEFF 来, Unicode 中称之为 BOM, 接下来就让我们一起来了解有关 BOM 的知识, 在此之前我们需要说说有关 端法 的知识.
在具体介绍它之前, 让我们先看看鸡蛋的两种摆法:
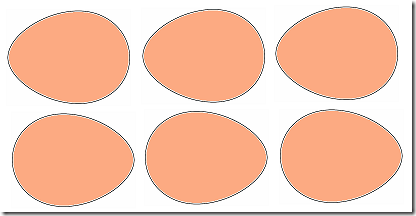
大家看出区别来了吗?
画得不咋的, 大家凑合看就是了, 画出了<<蒙娜丽莎>>(Mona Lisa)的达芬奇(Leonardo da Vinci)据说开始学画画时也画过一段时间鸡蛋呢, 有说画了几天的, 也有说画了几年!
如果按照我们从左到右的习惯认为左是前面, 上面可以说是 小端在前, 而下面的则是 大端在前. 有人可能要问, 这与我们的 BOM 有何关系? 我们知道 UTF-16 一个代码单元有两个字节, 如果把一代码单元比作一个鸡蛋, 那么它也有两个端, 一个字节是小端, 另一个则是大端.
摘要: 本文主要讲述 string.getBytes() 方法, 分析了系统缺省编码的各种陷阱, 并针对测试中出现的乱码作了初步的分析, 对代码页的概念也进行了介绍.
在前一篇里我们谈了 Unicode 的代码单元及 string.length, 现在接着前面的讨论继续谈 string.getBytes() 方法并对乱码的产生作初步分析.
首先声明一下, 以下讨论如无特别说明, 均是在 Java 语言环境下. 如果你用的不是 java, 我只能说声抱歉. 但另一方面, 我相信无论是何种语言或平台, 也必然有类似的方法及类似的处理, 而其中的原理也必将是相通的, 当然了, 具体到细节上则可能会有些差异.
摘要: 本文讲述了 Unicode 中的代码单元这一概念, 并以 java 为例, 阐述其对 string.length 方法的影响, 并结合 junit 做了一些具体的测试.
在前一篇章中已经谈了不少 Unicode 中的重要概念, 但仍还有一些概念没有提及, 一则不想一下说太多, 二则有些概念也无法三言两语就说清楚, 本文在此准备谈一下 代码单元 及由此引发的一些话题.
代码单元指一种转换格式(UTF)中最小的一个分隔, 称为一个 代码单元(Code Unit), 因此, 一种转换格式只会包含 整数 个单元.
{kind=link}