
在说完了网页中的编码与乱码(一, 二, 三, 四, 五 ), servlet 中的编码问题 后, 这次来探讨一下 JSP 中的编码与乱码问题.
在之前, 曾谈到过 JSP 与 HTML 间的关系, JSP 本质上是一个 HTML 的模板, 用于在服务端动态生成 HTML, 这点跟 servlet 是类似.
其实 JSP 本质就是 servlet, 一个 JSP 页面它会被编译成一个 java 文件, 实际上就是一个 servlet 类(或其子类, 在文章的后面会具体讨论这个问题).
一个具有多个编码的 JSP 页面
关于 JSP 中的编码设置, 有好几处的地方值得注意. 用一个例子来说吧, 比如下面这个叫 testEncoding.jsp 的页面:
<%@ page language="java" contentType="text/html; charset=utf-8"
pageEncoding="gbk"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="iso-8859-1">
<title>一个 jsp 测试页面</title>
</head>
<body>
一个 jsp 测试页面。<br>
<% out.print("测试 jsp 编码"); %>
</body>
</html>
有三处地方出现了编码相关的信息(contentType, pageEncoding, meta charset), 而且还是矛盾的, 有 utf-8, gbk 和 iso-8859-1. (正常情况下你应该保持三者一致)

那么现在问题来了:
- 这个源文件到底是什么编码?
- 最终生成并发送到浏览器的字节流又是什么编码?
- 会不会出现乱码? (包括用编辑器打开以及在浏览器中打开时)
这三个矛盾的编码可能还是会让很多人困惑的, 可能会觉得被搞晕了, 下面将一一分析以上问题.
源文件的编码与 pageEncoding
自然, 需要明白 @page 指令中各个属性的含义, 比如 contentType, 有了前面的 网页中的编码与乱码(3) 的基础等, 应该不难猜出它就是指定了 response header 中的 content-type 字段的值.
那么 pageEncoding 又是什么呢? 其实从字面上也不难猜出, 它就是页面的编码, 也就是这个 JSP 源文件本身的编码.
在 eclipse 中, 在文件上"右键--属性(properties)", 在弹出的属性框中可以发现文件的编码本身就是 gbk:
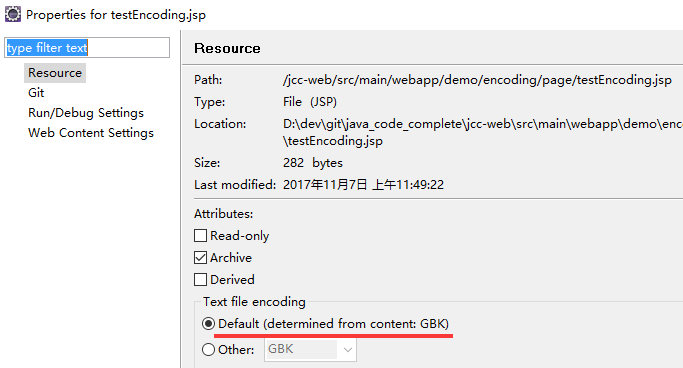
而且它还加了一句话(determined from content: GBK), 也就是从内容中推断出来的.
而页面的内容中不就是 pageEncoding 那里才有 gbk 吗, 所以这个属性就是源文件编码本身. 如果你调整了它的值, 推断出的值也会跟着改变, 你可以自行试试.
注意: 只有智能的编辑器(比如专门的 JSP 编辑器)才能做这些推断, 普通的编辑器是不行的. 在前面的 网页中的编码与乱码(2) 中曾经谈过这个问题.
JSP 页面编码的官方参考
关于 JSP 页面编码的官方参考见这里: https://docs.oracle.com/cd/E19316-01/819-3669/bnayf/index.html
在此官方文档里它提到:
For JSP pages, the page encoding is the character encoding in which the file is encoded.
For JSP pages in standard syntax, the page encoding is determined from the following sources:
The page encoding value of a JSP property group (see Setting Properties for Groups of JSP Pages) whose URL pattern matches the page.
The pageEncoding attribute of the page directive of the page. It is a translation-time error to name different encodings in the pageEncoding attribute of the page directive of a JSP page and in a JSP property group.
The CHARSET value of the contentType attribute of the page directive.
If none of these is provided, ISO-8859-1 is used as the default page encoding.
简单翻译一下, JSP 页面编码的确定有四个途径(越前面的优先级越高):
- JSP 属性组(JSP property group)中的配置.
page指令中的pageEncoding属性.page指令中的contentType属性下的charset的值.- 以上均无提供, 使用缺省值, 具体为 ISO-8859-1.
由上可见, pageEncoding 属性它的优先级还不是最高的, 最高的是 JSP 属性组中的配置, 这个到底是什么呢?
JSP 属性组中的 page-encoding
其实它就是 web.xml 中的一个配置项, 比如下面就配置了一个全局的 JSP 文件编码, 值为 utf-8:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://java.sun.com/xml/ns/javaee"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
<display-name>jcc web demo</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
<!-- 指定 jsp 文件的编码 -->
<jsp-config>
<jsp-property-group>
<url-pattern>*.jsp</url-pattern>
<page-encoding>utf-8</page-encoding>
</jsp-property-group>
</jsp-config>
</web-app>
具体为 jsp-config 标签下的 jsp-property-group 标签下的 page-encoding 标签所指定的值, 再结合 url-pattern 标签指定一个适配范围.
假如增加以上配置, 那么它这里配置的 utf-8 实际上与现在这个文件中的 pageEncoding="gbk"是冲突的, 这种不一致会导致 servlet 容器(这里也就是 tomcat)报错:
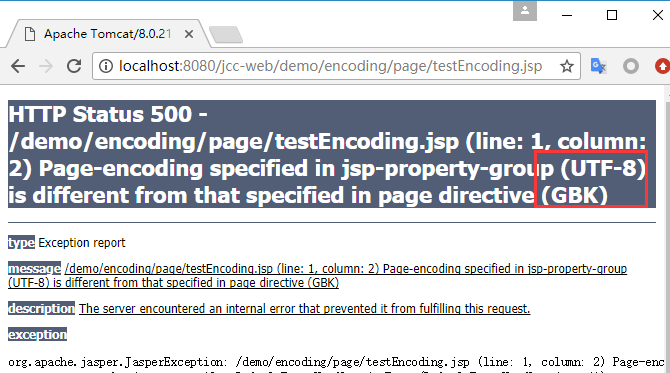
既然你在 web.xml 中配置了 page-encoding, tomcat 遵循 JSP 规范会优先采纳它.
这也很好理解, 既然你都专门配置了来告诉我文件的编码, tomcat 都不需要自己去检测了, 它何乐而不为呢?
但它接着又发现文件里面还指定了 pageEncoding, 值与配置的还不一致, 于是它就被搞糊涂了, 抛出了以上异常, 抱怨两者不一致.
其实是 JSP 中的规定, 说不一致就抛异常, tomcat 作为一个 servelt 容器只是遵循了这些规范.
另: 手动测试时, 当在 web.xml 中增加配置后, 你可能需要清理一下 tomcat 的缓存, 以确保 JSP 文件被重新读取编译等.
所以, 配置这种全局属性要小心, 要么不要采用它;要么可以通过 url-pattern 缩小匹配的范围, 确保它只应用在正确的文件或文件夹下.
另一方面要保证保存文件的真实编码确实使用了配置的值. 这点 在前面 也一再强调过.
由前面的优先级还可以知道, 假如没有 JSP 属性组的配置, 也没有 pageEncoding 属性, 则会用 contentType 中的 charset 值作为页面的编码.
尽管这个值实际是给响应流用的. 在前面的 网页中的编码与乱码(3) 篇章中曾详细讨论过这个问题.
那么现在清楚了, 这个 JSP 文件本身的编码是 gbk, 但它也可能受一些全局性配置的影响.
智能的 JSP 文本编辑器会采纳 pageEncoding 的值来保存, 当然, 如果不是智能的编辑器, 情况就不好说了, 你完全可以在保存时自己指定一个编码.
响应流中的编码
以上就是第一个问题, 接下来讨论第二个问题: 最终生成并发送到浏览器的字节流又是什么编码?
是 pageEncoding 中指定的 GBK 呢? 还是 contentType 中指定 UTF-8 呢? 亦或是 meta charset 中的 ISO-8859-1 呢?
如果在浏览器中访问这个页面, 中文是能正确显示的:
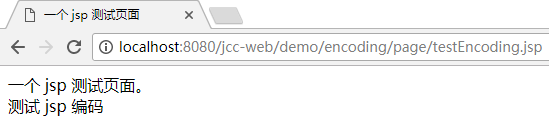
这说明肯定不是 ISO-8859-1 了. 再看 response 中的具体内容, 也就是最终生成的 html, gbk 什么的也全部消失了, 只有 meta charset 还在:
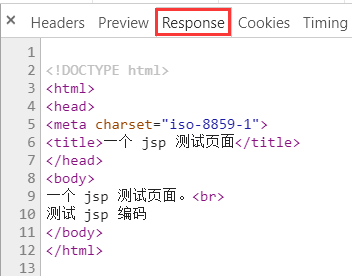
再看 response header 中的 Content-Type, charset 是 utf-8:
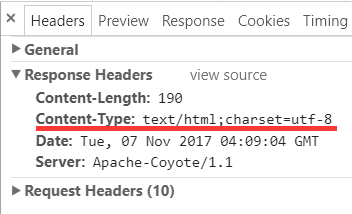
所以, 响应流的编码实际就是 utf-8.
响应流编码的官方参考
关于这个响应流的编码, 同样有官方文档: https://docs.oracle.com/cd/E19316-01/819-3669/bnayg/index.html
具体来说是这样的:
The response encoding is the character encoding of the textual response generated by a web component. The response encoding must be set appropriately so that the characters are rendered correctly for a given locale. A web container sets an initial response encoding for a JSP page from the following sources:
The CHARSET value of the contentType attribute of the page directive
The encoding specified by the pageEncoding attribute of the page directive
The page encoding value of a JSP property group whose URL pattern matches the page
If none of these is provided, ISO-8859-1 is used as the default response encoding.
简单翻译一下, 它由以下几个步骤来确定响应流的编码(越前面的优先级越高):
page指令中的contentType属性下的charset的值.page指令中的pageEncoding属性.- JSP 属性组(JSP property group)中的配置.
- 以上均无提供, 使用缺省值, 具体为 ISO-8859-1.
发现什么规律没有呢? 前面三项与之前的确定页面编码的顺序恰好是相反的, 也就是 contentType 中的值这时反而是优先级最高的;没有 contentType, 才会看 pageEncoding.
所以在这个例子中, gbk 只是作为文件编码, tomcat 用它来把源文件正确读取上来, 之后就没有它什么事了.
而假如前两者都不存在, 就会采用 JSP 属性组中的值, 就是前面介绍的那个 web.xml 中的 page-encoding 配置(假如有的话).
最后, 假如以上手段都不能确定, 就用缺省值 ISO-8859-1.
从 JSP 到 Servlet 再到 HTML
其实 JSP 文件会被转换成一个 Java 文件, 在这个例子中, 具体在我的电脑上, 可以去到 D:\dev\wp\neon3\workspace.metadata.plugins\org.eclipse.wst.server.core\tmp0\work\Catalina\localhost\jcc-web\org\apache\jsp\demo\encoding\page 下,
这个文件夹的前面部分就是上一篇 Java servlet 使用 PrintWriter 时的编码与乱码 介绍的 tomcat 启动命令行中的
–Dcatalina.base中的值:
不同的部署方式具体情况可能会有所差别. 不同的 server 甚至不同的 IDE 工具, 请自行查阅资料了解具体部署到的地方.
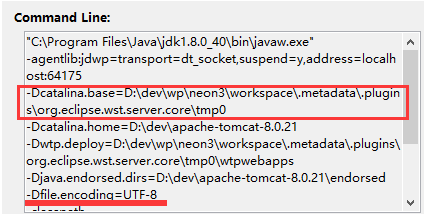
可以发现一个 testEncoding_jsp.java 和 testEncoding_jsp.class 的文件:
与 testEncoding.jsp 是对应的(从名字与所处位置都不难推测出来). 它的内容如下:
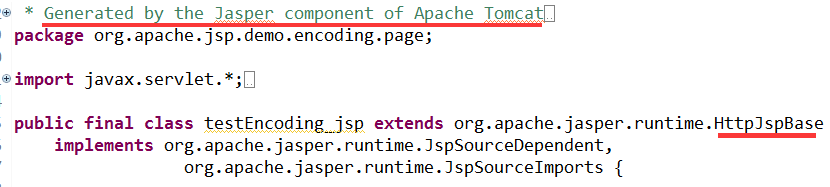
从开头的注释可以看出它是由 tomcat 的 Jasper 组件生成的, 继承自 org.apache.jasper.runtime.HttpJspBase 这个类.
把这个文件导入某个 web 工程中, 查看其类型层级(在 eclipse 中, 具体操作为: 菜单--Navigate—Open Type Hierarchy):
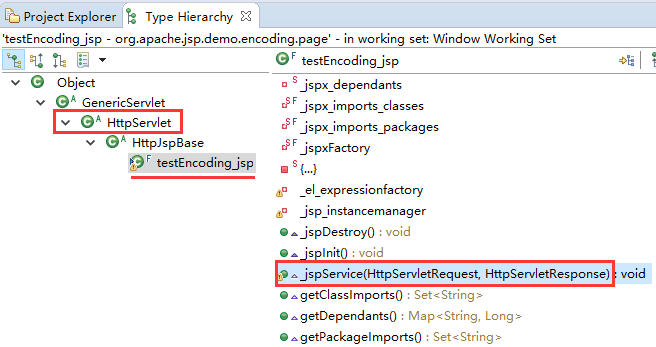
在左侧的继承树中可以看到它继承了 HttpJspBase, 而后者又继承了 HttpServlet , 所以它实际上就是一个 servlet.
在右侧的方法和属性列表中还可以看到它有个 _jspService 方法, 有 request 和 response 两个参数, 实际上就类似于 servlet 中的 service 方法.
去到这个 _jspService 方法中看一下, 将其中部分内容(只截取了关键部分, 因为整个方法比较长)与原来的 JSP 页面及最终的 html 输出对比的话:
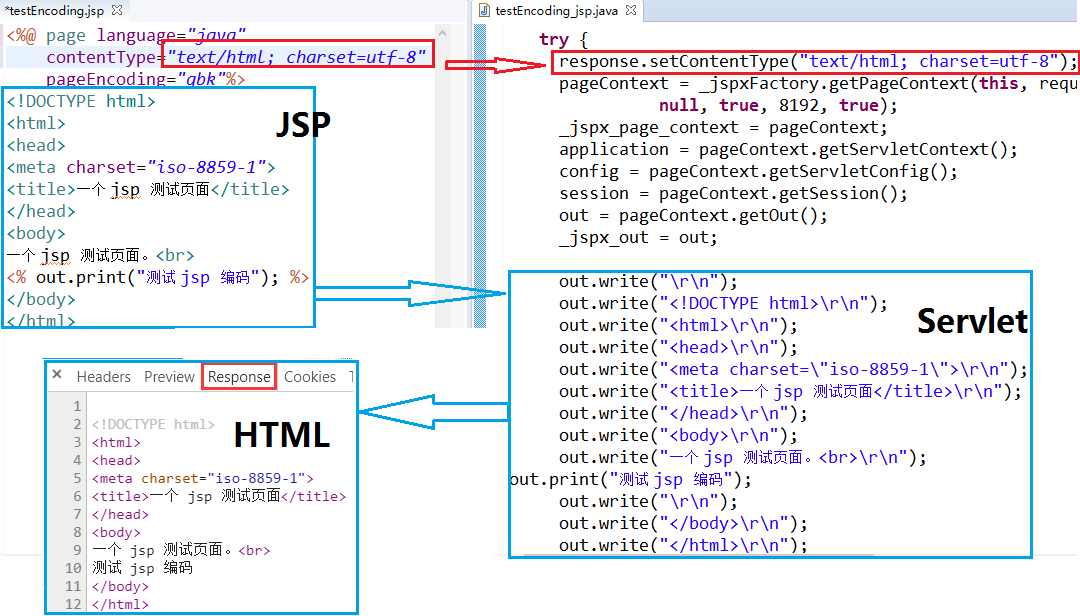
不难看出, jsp 中 page 指令中的 contentType 的值就成了 servlet 中的 response.setContentType 的值, 最终成为前面提到的浏览器中 header 响应中的 Content-Type:
而 jsp 中的 java 脚本(<%%> 部分的代码)就直接转换成了代码;其它 jsp 中跟 html 一样的标签在 servlet 中就直接用 out.write 输出了, 最终 out 输出的结果就是在浏览器端看到的 response 的内容, 也就是最终的 html 页面.
pageEncoding 在这里已经不存在了. 那么, 至此, 第二个问题答案也清楚了, 响应流用 utf-8 编码.
会不会乱码?
最后一个问题, 会不会出现乱码? (包括用编辑器打开以及在浏览器中打开时)其实答案也很清楚了.
前面 网页中的编码与乱码(3) 提到, response header 中的 Content-Type 下的 charset 编码具有比 html 页面中 meta charset 声明的值更高的优先级, 所以浏览器会选用 utf-8 而不是 ISO-8859-1 来解析, 所以页面显示也是正常的.
而编辑 jsp 文件时, 智能的编辑器会检测到正确的编码, 是可以正常打开这个文件的. 而普通的编辑器就不好说了, 会受很多因素影响, 比如所在系统环境的缺省编码设置, 以及编辑器本身是否具有一定的编码探测能力等等, 也可能会正常打开, 也可能在打开时乱码.
示例代码(gitee)
最后, 文中示例的代码可见我的码云: https://gitee.com/goldenshaw/java_code_complete/commit/33f03921214a31b052a0e968805652dd0d46f849
好了, 关于 JSP 中的字符集编码与乱码问题的探讨就到这里, 在正常的开发活动中, 你应该始终注意保持几处编码的一致, 比如始终在各处统一使用 utf-8 编码, 这样就能避免绝大多数问题.