
在之前说完了静态 html 页面的中的编码(一, 二, 三, 四, 五 ), 接着又谈论了动态 html 页面中的编码问题, 具体以 java 平台为例, 谈论了 , servlet 中的编码问题 以及 jsp 中的编码与乱码问题.
虽然没有涉及更多的语言平台, 比如 php, asp, 乃至 nodejs, python, ruby 等, 但背后的原理基本也是相通的.
这一次将转入一个新的话题, 就是 URL 中的编码与乱码问题.
带有中文的 URL
我们依然从一些简单的实验开始去探讨, 而不是直接给出一些结论. 先创建两个有着中文文件名的 html, 页面编码分别是 utf-8 和 gbk;以及一个中文名的文件夹, 下面再放一个普通的 html 文件, 如下所示:
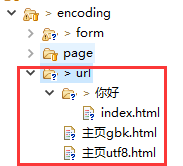
自然, 你可能听说过很多前辈们的警告: 千万别用中文作文件名或路径名(文件夹名). 这种警告应该说是中肯的, 但也不意味着用了中文就一定有问题.
前面三个文件的内容如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>位于中文文件夹下的文件</title>
</head>
<body>在【你好】 文件夹下的 index.html
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="GBK">
<title>带中文的 URL(GBK)</title>
</head>
<body>
测试带中文的 URL,页面编码为:GBK
<br> 中文链接:
<a href="你好/index.html">你好/index.html</a>
<br> 中文链接并带有中文查询字符串:
<a href="你好/index.html?s=你好">你好/index.html?s=你好</a>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>带中文的 URL(UTF-8)</title>
</head>
<body>
测试带中文的 URL,页面编码为:UTF-8
<br> 中文链接:
<a href="你好/index.html">你好/index.html</a>
<br> 中文链接并带有中文查询字符串:
<a href="你好/index.html?s=你好">你好/index.html?s=你好</a>
</body>
</html>
在前面两个文件中还使用了一个 a 标签的超链接, href 中的内容也是包含有中文的:
<a href="你好/index.html">
有的还带有中文的查询字符串:
<a href="你好/index.html?s=你好">
把以上部署到 tomcat8 中, 然后在 chrome 中访问【主页utf8.html】 文件:
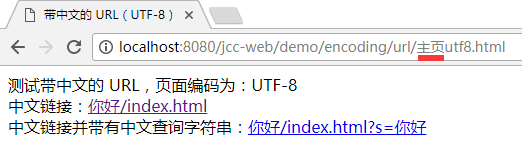
首先, 打开是没有问题的, 地址栏的链接也是中文, 不过地址栏这里浏览器为了对用户友好, 实际上使用了一点障眼法. 如果你把地址栏的内容拷贝出来, 粘贴到一个文本文件上, 会发现实质的内容是这样的:

又或者你打开"开发者工具", 在其中的请求头标签页下查看:
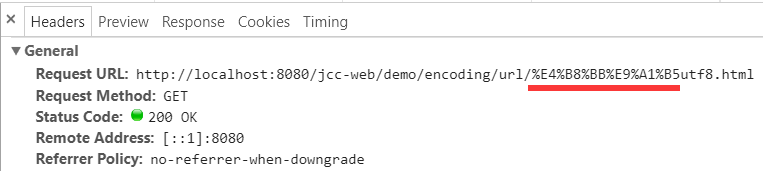
会发现【主页】两个汉字被取代了, 真正的内容是 "%E4%B8%BB%E9%A1%B5" 这样一串字符.
URL 中的转义表示
那么, 像这样的一串字符 "%E4%B8%BB%E9%A1%B5", 其中的每一个部分用【%XX】来表示, 其中 XX 表示一个十六进制的数(hexadecimal digits), 这样的表示就是所谓的 URL 的转义表示, 也叫 百分号编码(Percent-Encoding).
如果把其中的百分号 % 去掉, 会发现结果是"E4 B8 BB E9 A1 B5", 总共 6 个字节, 其实就是"主页"两字的 utf-8 编码.
如果你还记得先前说到的 utf-8 的编码模式, EX XX XX 通常就是常用汉字的模式.
那么现在比较清楚了, URL 路径中的中文需要转义, 具体编码用的是 utf-8.
为什么 URL 中中文需要转义
你可能会想, 为什么 URL 中的中文要转义呢? 转成那样一串东西, 猛看上去也不知道它到底代表什么汉字, 怪怪的. 那么这个原因简单讲就是 URL 中的规范就是这么规定的.
更准确地说是 URI 规范. URL 是 URI 的一种, 常见的 URI 通常也都是 URL, 一般情况下会混着用两者.
关于 URI 规范, 具体可见 http://www.ietf.org/rfc/rfc2396.txt 和 http://www.ietf.org/rfc/rfc3986.txt. (后面的为更新的规范)
URI 规范中对于转义的规定
考虑到 URI 在各种平台间传输时的兼容性, URI 规范中规定只有 US-ASCII 字符集中的字符可以直接出现在 URI 中. 事实上, 甚至 ASCII 本身的许多字符也不允许直接出现在 URI 中, 有的也要转义.
可以直接用的有 26 个大小写字母, 10 个数字, 还有以下四个标点符号:
-, 短横(中划线)., 点号_, 下划线~, 波浪线
其它的有的属于 保留字, 用作为 分隔符(delimiters), 它们有:
:, 冒号/, 正斜杠?, 问号#, 井号[, 左中括号], 右中括号@, 地址符号!, 感叹号$, 美元符号&, 与', 单引号(, 左小括号), 右小括号*, 星号+, 加号,, 逗号;, 分号=, 等号
比如正斜杠 / 就是一个最常用的分隔符. 如果想在 URL 中包含这样符号, 又不想它们被解析为分隔符, 就要对其转义.
分隔符还具体分为 通用分隔符 和 子部件分隔符, 具体什么时候需要转义的细节参见上述提到的规范.
其它的还有一些不可以打印的字符也要转义, 比如 空格 等.
所以, URI 中可用的字符实际是比较有限的, 最好只使用那些安全的字符, 就是 26 个字母加数字.
如果用了其它, 就免不了要转义, 然后各种编码, 解码, 通过各种网关, 代理, 各种转发过程时等也容易发生错误.
浏览器对中文路径 URL 的转义
比如上面说到的中文, 那就要转义, 虽然在 href 中直接写的是中文, 但正规的浏览器都会对其先转义然后才发送请求.
比如, 在上述页面中, 继续点击其中的链接 "你好/index.html":
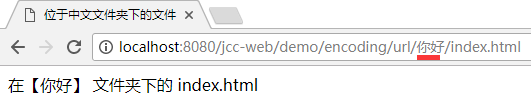
就进入了那个中文文件夹路径下, 具体查看一下请求, 发现也是转义了的:
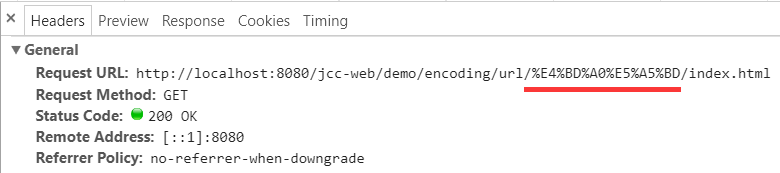
虽然在 href 中是直接写的中文, 但浏览器悄悄地做了转义.
当然你也可以自己先行转义好放在
href那, 具体请参考urlEncode等方法, 这样浏览器就不会再转了.
tomcat 与 URIEncoding 设置
另一方面, 除了浏览器这边的转义外, server 端也要能正确地解码. 其实这里把它部署到 tomcat8 中, 没有出现问题, 但假如是部署到 tomcat7 中, 再请求时会发现 404 错误, 找不到文件了:
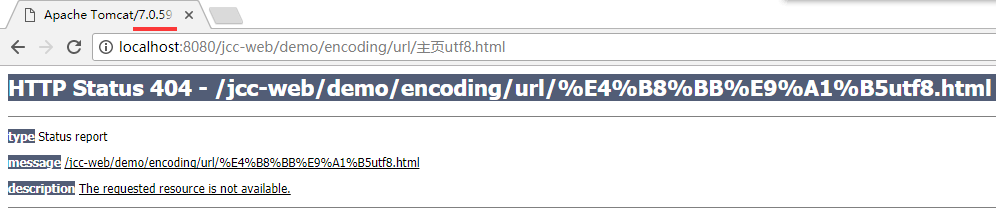
请求的 url 还是一样的, 也是转义的了, 但是问题出在 tomcat7 接受到这个转义 url 的处理上, 原来它默认是按 iso-8859-1 来解码的, 导致无法正确地得到 "主页utf8.html", 因此就出错了.
为此, 还要去到 server 的配置文件目录下, 找到 server.xml:
再在 server.xml 文件中找到端口为 8080 的那个 Connector, 增加一个设置 URIEncoding="UTF-8", 这样之后才能正常:
也即这样:
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443" URIEncoding="UTF-8"/>
那为什么 tomcat8 又 OK 呢? 原来从 8 开始(具体为 8.0.0-RC3), 这个默认值改为了 utf-8, 于是就不用你自己去设置了. 具体见: https://wiki.apache.org/tomcat/FAQ/CharacterEncoding#Q2
其实严格地讲, 还会受一个叫 "strict servlet compliance" 的设置的影响, 这个设置默认是 off, 这时的值就是 utf-8;
而假如为 on 的话, 表明严格地遵循 servlet 规范, 此时即便在 tomcat8 下也是 iso-8859-1, 那么就也要手动配置这个值.
如果你用的不是 tomcat, 那么你要自行查阅资料了解缺省值的配置.
由于篇幅关系, 涉及到 gbk 页面下的测试及查询字符串相关的一些情况留待下篇再分析.