
在上篇中, 初步谈论了 URL 中含有中文字符时的转义编码, 提到了所使用的编码是 utf-8.
不过你可能会有点疑问, 一定都是要用 utf-8 编码吗? 还是因为页面编码本身是 utf-8 的缘故呢? 毕竟在那个例子中, 页面的编码也恰好是 utf-8.
在 GBK 编码页面下的 URL 转义
这次, 将继续测试页面编码是 gbk 时的情况, 如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="GBK">
<title>带中文的 URL(GBK)</title>
</head>
<body>
测试带中文的 URL,页面编码为:GBK
<br> 中文链接:
<a href="你好/index.html">你好/index.html</a>
<br> 中文链接并带有中文查询字符串:
<a href="你好/index.html?s=你好">你好/index.html?s=你好</a>
</body>
</html>
打开时, 是正常的:
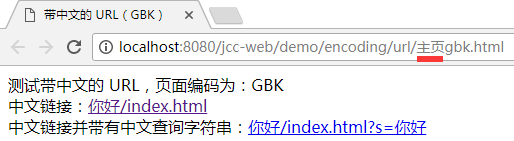
当然, 你可能会想, 打开前, 还不知道页面的编码呢, 那么事实上也是如此, 此时请求的 url 依然是 utf-8 编码的:

那么继续点击其中的"你好/index.html"链接时呢? 结果页面还是 OK 的:

查看其发出的 url:

尽管此时在 gbk 编码的页面发出此请求, 但它的编码还是 utf-8.
那么是否就可以得出结论, 即 url 中的编码始终是用 utf-8 呢? 然而事情没有那么简单, 正像你看到页面中还有一个链接, 下面那个带有中文 查询字符串 的链接:
你好/index.html?s=你好
在 gbk 页面下点击它时是怎样的情况呢? 在此之前, 先要对 URL 中的结构做些了解.
URL 中的结构简介
多数的 URI 结构可以这样去划分:
<scheme>://
: @<host>:<port>/<path>; ?<query>#<frag>
下面从一些例子中具体介绍各个部分的含义. 一个具体例子:
https://xiaogd.net:443/?p=1699
其中:
- scheme(协议, 方案)为 https;
- host(主机名, 域名)为 xiaogd.net,
- port(端口)为 443;
- query(查询字符串)为 p=1699.
这是上一篇文章的一个短连接(short link), 点击它会重定向到上一篇章中(已失效).
注: 这个例子中, 没有用户名, 密码, 没有路径(path)(也可以认为有一个路径, 就是根路径"/"本身), 没有 params, 也没有 frag. https 协议的默认端口即为 443, 通常可以省略.
其中查询字符串 query strings, uri 规范中的标准叫法为 query component(查询组件), 用分隔符问号 "?" 与其它部分隔开, 具体内容可以由多个 键值对 组成, 中间由 "&" 符号分隔, 键与值之间用分隔符等号 "=" 隔开:
如: http://localhost/foo?userid=9527&gender=male 中的查询字符串有两个键值对:
- userid=9527
- gender=male
另一个例子:
http://exp.xiaogd.net:80/demo/css/stroke-animate/stroke-animation.html
其中, 路径 path 为 /demo/css/stroke-animate/stroke-animation.html.
注: http 协议的默认端口即为 80, 通常可以省略;如果不是 80 就不能省略, 如测试常用的 8080 端口, 就要显式地在 url 中带上, 这一端口来自于 web server 启动时所绑定(监听)的那个.
frag(fragments, 片段, 分段) 是页面内的链接(锚点), 位于最后, 用井号(#)跟其它部分隔开, 严格地讲它不属于 url 的一部分, 它的值通常即为页面内某个标题元素的 id. 一个具体例子:
https://www.xiaogd.net/url-中的编码与乱码(上)/#tomcat与URIEncoding 设置
点击它与点击 https://www.xiaogd.net/url-中的编码与乱码(上)/ 都是跳到同一个页面, 但它会滚动到页面内的某个元素下(通常为某个子标题), 跟你打开这个页面单击那个目录下的标题类似:

其实上图目录下的就是这种页面内的锚点(frag), 分享一个比较长的页面时, 这种方式能够更加精准地定位到页内的某个段落上, 免得别人去翻找.
你可以亲自点击上述两个链接看看结果有什么不同!
其它的一些例子如:
包含有其它一些协议, 如 ftp;还有用户名, 密码的例子, 以及 param 的例子.
这些例子来自 <<Http 权威指南>> 一书中.
param 跟查询字符串 query 很类似, 跟在 path 后面, 用分号";"与 path 隔开, 但这种用法很罕见, 反正我是没怎么见过用 param 的, 一般都是用 query.
URL 查询字符串(query component)中的编码
这里主要关注 query, 在明白它是怎么回事后, 在 gbk 页面下点击带有中文查询字符串的链接时:
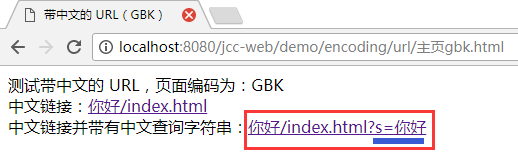
结果是这样的:

会发现情况有不同了, 地址栏中路径上的"你好"两字还能正确显示为中文, 但后面的查询字符串中的"你好", 同样的字符此刻却显示为一串转义字符 "%C4%E3%BA%C3".
从四字节的编码 "C4 E3 BA C3" 来看, 显然是 gbk 编码, 而不是 utf-8 编码, 因为对于 utf-8 而言, 常见汉字一个字符至少也是三字节的编码, 而现在是一个字符两字节, 所以显然是 gbk 编码.
此刻去看请求头中的 url:

虽然同样是 "你好" 两字符, 编码却出现了不同. 在路径中是 utf-8 编码, 在查询字符串中却是页面的编码, gbk.
而当在页面的编码是 utf-8 的页面中点击同样的链接字符串作跳转时, 编码则是一致的:
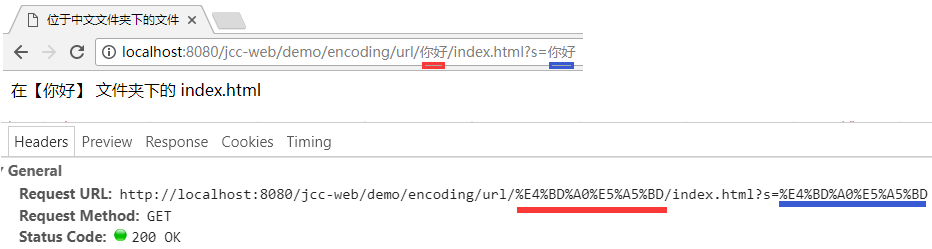
可以看到地址栏此刻都显示为"你好", 而请求头中的真实 url 两处的编码也确实是相同的.
综上, 可以得出这样一个结论: URL 路径中的转义使用 utf-8 编码, 但查询字符串中的转义却是跟随页面编码的.
在其它浏览器中的测试
在火狐浏览器(firefox)中的测试也能得出类似结论, 这里不再列举.
在微软的 Edge 和 IE(11)中测试则有些要注意的, 即使是在 gbk 页面下点击, 地址栏的显示始终是一致的:
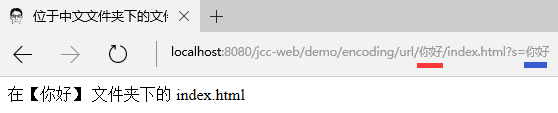
这个地址栏的值拷贝出来它也是字符形式, 而不是转义的形式, 这跟 chrome 等浏览器的行为又不一样. 当用开发人员工具查看请求头时:

显示是混乱的, 从某些字符来看, 像是使用了同一种编码, 但有的有转义, 有的又没有. 这个地方应该是它的调试工具本身的 bug.
如果在外面用 Fiddler 抓包工具查看, 发现它其实还是跟 chrome, firefox 一样的, 路径用 utf-8, 查询字符串跟随页面编码:
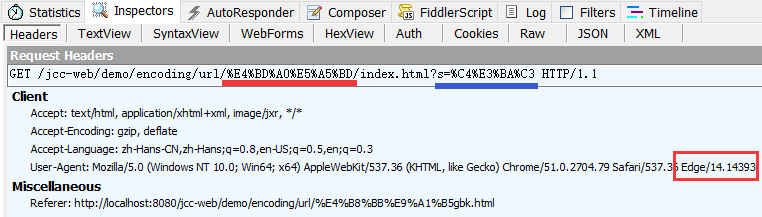
IE 11 跟 Edge 的行为类似, 而模拟一些更早的 IE 版本时, 比如 IE 9, 情况又有所不同:
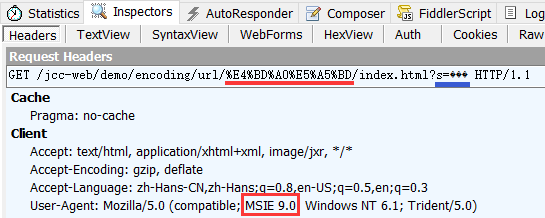
路径处还是 utf-8 的转义形式, 但是查询字符串中显示一些乱码的字符, 查看其十六进制形式时:

发现编码确实为 gbk, 但它没有转义. 当页面编码为 utf-8 时, 查询字符串的编码也是 utf-8, 但同样的, IE 9 不会自动帮我们把查询字符串转义.
更多的浏览器及版本下的行为, 这里也无法一一去测试, 读者如果碰到问题, 可自行具体分析.
URL 编码使用的总结与建议
所以, 总结来说:
- url 路径中的中文, 浏览器会自动进行 utf-8 编码转义;
- 查询字符串中, 现代浏览器会使用页面编码来转义;
- 查询字符串中, 较早期的浏览器也会用页面编码, 但不会为你转义, 你要自己做转义.
另外, 前面提到, server 端也要作相应处理, 比如 tomcat 中你可能要配置 URIEncoding, 而如果你的 url 中如果有多种编码方式共存, 处理起来会非常棘手, 甚至是不可能的.
如果页面要用 gbk 编码, 那么 url 路径中就不要带有中文了, 这时就查询字符串中有转义的 gbk 编码, 可以避免出现两种编码, 这时可在 URIEncoding 中设置为 gbk 来正确接收 url .
如有可能, 最好在所有环节使用 utf-8 编码, 在需要转义的地方, 手动地进行转义, 如此放可保证在各种情况下不会出现问题.
关于 URL 中的编码与乱码的介绍就到这里, 这里虽然也涉及到了用查询字符串向后端服务器传递参数, 但暂时还没有在服务器端尝试接收这些参数, 参数接收的话题将在后续的表单(form)提交时的编码与乱码中一起讨论.