
在上一篇我们谈论了 BOM 编码的页面, 并知道了它是有最高优先级的. 而这一篇将讨论最后的一个主题, 也就是缺省的情况. 既然名为缺省, 也就不难想到, 它的优先级是最低的, 也即是在其它情况下都无法确定编码时, 才轮到它上场.
缺省
前面说到, 缺省就是没有 BOM, 响应头中的 Content-Type 也没有 charset 声明, 文档内也没有 meta charset 的声明, 这时浏览器该如何确定 html 页面的编码呢? 这里将设计一系列实验以探究这个问题.
构建一个缺省响应
首先是构建一个缺省的响应. 比如去构建一个 gbk 编码的文档, 自然就没有所谓的 BOM 了;然后用 gbk 编码保存这个文档, 但在文档内也不声明;之后配置服务器的响应头也不带 charset 信息. 这样一来, 浏览器收到这个文档流时无法获得任何有效的编码信息, 就将进入缺省的处理模式.
构建一个缺省的 gbk 文档时有几点要注意. 这点在前面的"文档内编码声明"章节也已经提到过, 特别是你在一个工程缺省编码为 UTF-8 的项目内创建这样的文档时更要注意, 当你删掉 meta charset="gbk" 的声明时, 智能的 IDE 编辑器可能会悄悄调整所使用的编码.
最好是在外部用记事本或 notepad++ 这样的通用文本编辑器来创建一个缺省的 gbk 编码的文档.
静态页面测试
假如现在已经正确构建好一个 gbk 的缺省文档, head 没有 meta charset 声明:
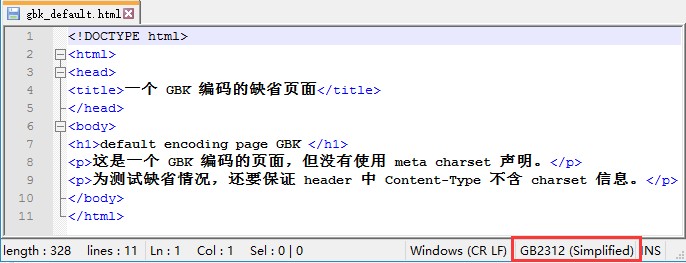
<!DOCTYPE html>
<html>
<head>
<title>一个 GBK 编码的缺省页面</title>
</head>
<body>
<h1>default encoding page GBK </h1>
<p>这是一个 GBK 编码的页面,但没有使用 meta charset 声明。</p>
<p>为测试缺省情况,还要保证 header 中 Content-Type 不含 charset 信息。</p>
</body>
</html>
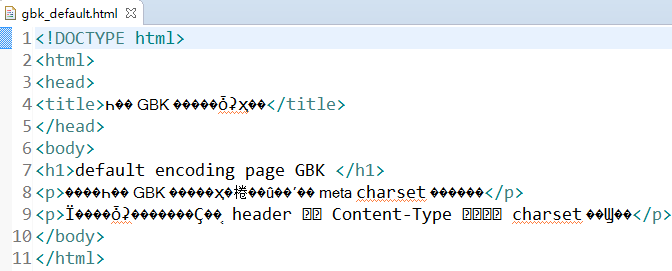
这样一个文档你在工程缺省编码为 UTF-8 的项目内, 比如 Eclipse 中打开时会是乱码(除非手动指定此文件的编码为 gbk), 因为智能的编辑器找不到编码声明, 就会用项目缺省编码去解析它:
之后还要确保 header 的 Content-Type 响应中也没有编码信息, 像这样:
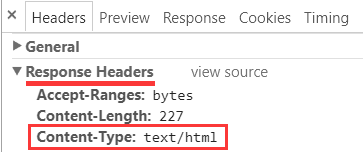
在我测试用的 tomcat8, 这里缺省就是这样不带编码信息, 如果你使用的服务器不是这样的, 那你还需要查询它的文档, 配置这个 Content-Type, 使之不带有 charset 信息, 确保它不会干扰我们的测试.
前面也已经强调过, 测试一定要在良好隔离的前提下进行, 否则将无法得出可靠结论!具体测试中也要注意观察实际的 header 响应中是否确实没有带 charset 信息.
在这样情况下, 浏览器将进入缺省模式:
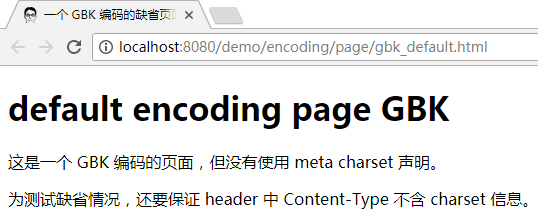
在我的电脑中测试是正常的:
当换了一个缺省为 UTF-8 编码同时不带 BOM 的文档时:
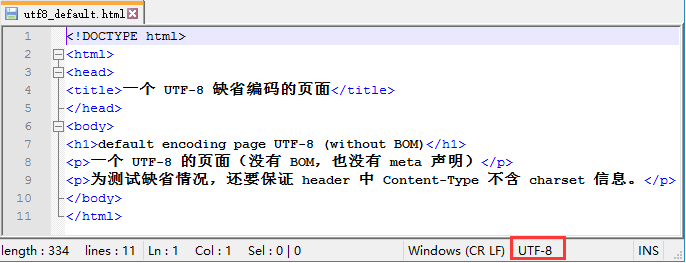
可以看到红框处编码显示为 UTF-8.(如果是带 BOM, 会显示为 "UTF-8-BOM", 具体见上篇中有关介绍)
<!DOCTYPE html>
<html>
<head>
<title>一个 UTF-8 缺省编码的页面</title>
</head>
<body>
<h1>default encoding page UTF-8 (without BOM)</h1>
<p>一个 UTF-8 的页面(没有 BOM,也没有 meta 声明)</p>
<p>为测试缺省情况,还要保证 header 中 Content-Type 不含 charset 信息。</p>
</body>
</html>
在 chrome 浏览器下测试却发现乱码了:
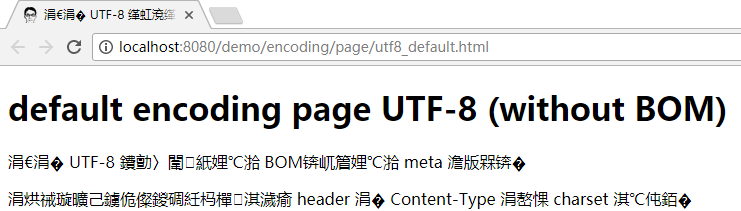
html 规范中的建议
那么以上情况给了我们什么启示呢? HTML 最新的规范中的建议是:
缺省情况下, 选择用户所在 地区语言 环境下最有可能使用的那个编码.
(In other environments, the default encoding is typically dependent on the user’s locale (an approximation of the languages, and thus often encodings, of the pages that the user is likely to frequent).)
在其列出的一个"语言地区--缺省编码"建议表中:

zh-CN 即我们中国大陆地区建议的缺省值为 "gb18030", 我国台湾地区则为 "Big5".
具体见: http://w3c.github.io/html/syntax.html#determining-the-character-encoding 中第 8 小点中的介绍.
所以, 在我们中国大陆地区, 缺省值即是国标系列的编码. (gb2312, gbk 和 gb18030, 后面的对前面是基本兼容的)
对于我们多数人而言, 电脑操作系统设置中, 地区设置是中国, 语言设置是简体中文, 那么这个缺省编码可以认为是 gb18030(或它兼容的 gbk, gb2312).
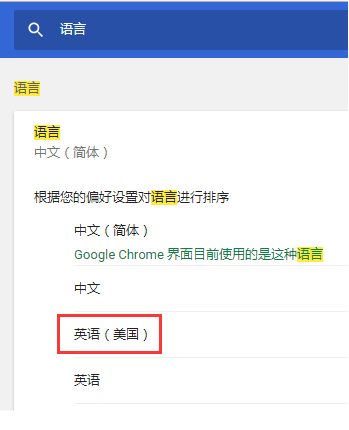
而在 chrome 浏览器中, 当我们调整地区语言设置后, 比如设置成"英语(美国)"
保存设置并重启生效后, 上述页面的展示效果会这样:
这个乱码模式很像是把它当作了 iso-8859-1. 根据上述的建议表, 英语(美国)不在建议表中, 因此隶属最后一项:
所有其它 locales, 缺省值为 windows-1252(这个编码跟 iso-8859-1 很多地方是相同的, 但也有一些具体差别, 详细情况这里不展开, 有兴趣的同学可以自行了解)
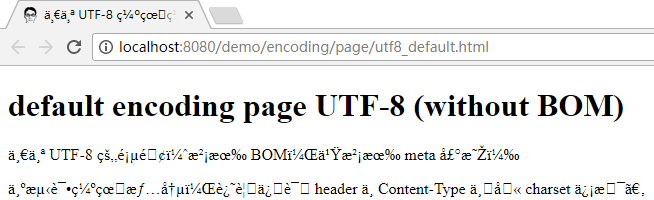

因此也不难理解, 缺省的 gbk 文档能够得到正常的显示, 而缺省的 utf-8 文档却显示为乱码.
尽管 utf-8 现在可能更流行, 并将越来越流行, 并且在越来越多的情况下是缺省编码的候选.
在其它的几个现代浏览器中(firefox 和 edge)的测试也是乱码:
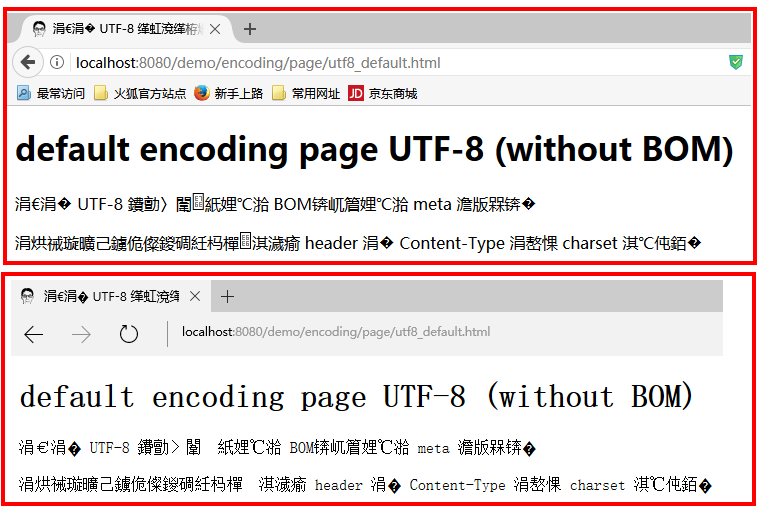
表明它们也都遵循了 html 规范中的建议.
但是, 在 IE 11 下测试时, 却没有乱码:

显然它没有很好地遵循 html 规范中的建议, 可能是它自己引入了某种自动检测机制来确定文档的真实编码.
不过考虑到 IE 这位大姑娘出道比较早, 所以你懂的, 当然是选择原谅她啦!
引入了某种自动检测机制的出发点可能是好的, 但浏览器过于仁慈或过于宽容有时却未必是好事.
我认为不应该试图去纠正用户的错误, 这可能掩盖了用户的失误, 把用户惯坏了并不是件好事.
那么知道了以上的混乱状况, 可以想象, 使用缺省绝不是一个好主意, 在开发中是应该尽量避免的, 否则你将很难预料在各种复杂的环境组合中, 页面是否还能正常显示. 记住, 缺省绝不是一个好主意!
动态响应测试
同理, 也可以为缺省情况构建动态的响应测试:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/encoding/page/default/gbk")
public class EncodingDefaultGBK extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html");
ServletOutputStream os = response.getOutputStream();
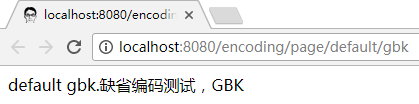
os.write("default gbk.缺省编码测试,GBK".getBytes("gbk"));
}
}
以上, 没有设置 header Content-Type 中的 charset 信息, 文档中也没有 meta charset 声明, 字节流实际使用 gbk 编码.
在浏览器中也能正常显示:
而如果实际用 utf-8 编码:
@WebServlet("/encoding/page/default/utf8")
public class EncodingDefaultUTF8 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html");
ServletOutputStream os = response.getOutputStream();
os.write("default utf-8.缺省编码测试,UTF-8".getBytes("utf-8"));
}
}
结果就还是乱码:
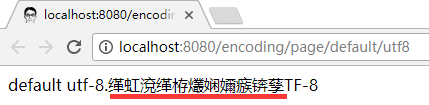
总结
说完了最后一种缺省的情况, 关于网页中的编码与乱码就介绍完了, 现在简单做个小结:
-
要保证不发生乱码, 最重要的是实际所用的编码要与宣称的一致, 无论是用 header Content-Type 形式还是 meta charset 形式(如果是 BOM, 则由编辑器来保证, 不用我们操心).
特别的, 要避免那种"嘴上说 gbk, 身体却是 utf-8", 挂羊头卖狗肉, 文不对题的情况.
-
如果多种编码声明方式并存, 也要保证几种声明方式的一致性, 并与实际所用的一致. 能做到这样, 也就不用担心优先级问题了, 否则, 按以下优先级处理:
- BOM
- header
- meta
- 缺省
这里主要注意 header 的优先级是高过 meta 的, 特别是配置了全局性 header 响应的情况下, 要使得所有的页面编码与其一致, 否则将容易出现问题.
-
不要依赖于缺省. 鉴于现实情况的复杂性, 缺省情况下的正常显示将很难得到保证.
示例代码 git
由于前面的代码示例都是用截图表示的, 如果有人想拷贝代码亲自实验, 我也已经上传至码云 gitee 上了, 静态页面部分可以到这里找到:
动态 servlet 部分:
参考资料
最后, 给出写作过程中参考的一些资料:
- https://www.w3.org/TR/html5/document-metadata#charset
- https://www.w3.org/International/questions/qa-html-encoding-declarations
- http://w3c.github.io/html/syntax.html#the-input-byte-stream
- http://w3c.github.io/html/syntax.html#determining-the-character-encoding
- https://www.w3.org/Protocols/rfc2616/rfc2616-sec3.html#sec3.4
- https://wiki.apache.org/tomcat/FAQ/CharacterEncoding
至此, 整个网页中的编码与乱码系列就结束了.
整个显得有点长, 因为不单单是告诉你一个结论, 而且还亲自构建了很多的测试去验证这些结论. 主要也是为了达成前面提到的一个目标: 尽量完整呈现分析一个网页编码与乱码的整个过程.
另一方面, 尽管这里介绍了很多的情况, 但我相信它依然无法涵盖现实中遇到的种种情况, 因此, 了解基本原理并掌握具体的分析方法是很重要的.
往后, 还会继续介绍其它的有关 web 编程方面的编码与乱码问题.