在上一篇中, 探讨了文件名编码以及非文本文件中的文本内容的编码, 在这里, 将介绍更为重要的文本文件的编码.
混乱的现状
设想一下, 如果在保存文本文件时, 也同时把所使用的编码的信息也保存在文件内容里, 那么, 在再次读取时, 确定所使用的编码就容易多了.
很多的非文本文件比如图片文件通常会在文件的头部加上所谓的 "magic number(魔法数字)" 来作为一种标识.
所谓的 "magic number", 其实它就是一个或几个固定的字节构成的固定值, 用于标识文件的种类(类似于签名).
比如 bmp 文件通常会以 "42 4D" 两字节开头.
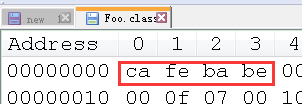
又比如 Java 的 class 文件, 则是以四字节的 "ca fe ba be" 打头. (咖啡宝贝? )
即便没有文件后缀名, 根据这些信息也是确定一个文件类型的手段.
附: 关于用 Notepad++ 查看十六进制的问题, 这是一个插件, 如果没有装, 菜单--插件--plugin manager--available--HEX-Editor, 装上它.
装上后, 它通常在工具栏的最右边, 一个黑色的大写的斜体的"H"就是它. 单击它可以在正常文本与 16 进制间切换. 要进一步查看二进制, 在文本区, 右键--view in--to binary.