
在前面我们说到了所谓的"计算机科学", 重点在于如何控制大型系统的复杂性.
复杂性本身当然也是个很大的话题, 而一种常见的复杂性的来源则是重复性, 即是由不断的重复所带来的复杂性.
重复性带来的复杂性常被人忽视, 大概是因为一开始它是不起眼的, 而当人们意识到它的存在时可能已经陷入了泥潭.
探讨了简单重复性所带来的复杂性.
在前面我们说到了所谓的"计算机科学", 重点在于如何控制大型系统的复杂性.
复杂性本身当然也是个很大的话题, 而一种常见的复杂性的来源则是重复性, 即是由不断的重复所带来的复杂性.
重复性带来的复杂性常被人忽视, 大概是因为一开始它是不起眼的, 而当人们意识到它的存在时可能已经陷入了泥潭.
介绍了什么是计算机科学, 以及为什么说它不是科学也与计算机无关.
什么是计算机科学呢? 我们可能很容易望文生义地理解为"不就是关于计算机的科学吗? "然而一位来自 MIT 计算机系的教授认为"计算机科学"不但不是科学, 而且而且还跟计算机无关!这是怎么回事呢?
视频链接见这里.
下面我们就来分享一下他对于计算机科学的看法, 算是某种读书笔记吧, 或者更准确地说是"看视频后的笔记".
由于视频时英文的, 以下重要观点都来自教授视频中的原话, 由于没有对应中文, 意思都是我自己翻译的, 由于个人水平有限, 为保证准确, 重要观点都附上原有的英文, 如果觉得翻译有误或有值得商榷的地方, 欢迎留言.
对于这个行业(business)来说, 计算机科学是个糟糕的(terrible)名字. 首先它 不是科学(not a science).
它也许是 工程(engeneer) 或者 艺术(art), 但它不是科学.
这种所谓的科学甚至与 魔术(魔法) 有很多相同点(has a lot in common with magic).
不过教授在此没有再继续深入讨论下去, 只是说将在后面的课程中看到这一点~
小编注: 到底什么才是科学呢? 很多人觉得自己知道什么是科学, 但也许其实只是很肤浅的认识.
如果你没怎么听过 "科学方法(scientific method)" 或者听过但只是觉得它不过是一个普通的名词组合而已, 那你也许还真没有理解什么是科学.
其次, 它实际上与计算机无也没多大关系(not really very much about computers).
它与计算机无关正像物理学不是关于粒子加速器的学问;
And it's not about computers in the same sense that physics is not really aboutparticle accelerators,
生物学也不是关于 显微镜与 皮氏培养皿的学问那样.
and biology is not really about microscopes and petri dishes.
它与计算机无关正像几何学并不只是关于使用测量工具的学问.
And it's not about computers in the same sense that geometry is not really about using surveying instruments.
事实上, 计算机科学与几何学间有许多的共同点. 早期, 埃及人认为几何就是对土地的测量.
geometry comes from Gaia, meaning the Earth, and metron, meaning to measure.
geometry 来自 Gaia(希腊神话中的土地神), 意思为土地(地球), metron 则意为测量.
现在, 我们认为计算机科学是关于计算机的原因就像埃及人认为几何就是关于测量仪器的那样.
当某一领域才刚开始, 我们还不能很好地理解它时, 就很容易到把所做事情的本质(essence)与所使用的工具相混淆.
it's very easy to confuse the essence of what you're doing with the tools that you use.
某种程度上, 我们对计算机科学本质的理解甚至还不如古埃及人对几何本质的理解.
那究竟什么才是计算机科学的本质呢? 什么又才是几何学的本质呢?
显然, 这些埃及人确实有去使用测量仪器, 但当我们在几千年后再来回顾这些古埃及人所做的事时, 我们说, 嘿, 他们到底做了什么?
那么其中最重要的事情, 就是开始**形式化(formalize)**关于空间和时间的观念,
formalize notions about space and time
开始一种**形式化(formally)**谈论数学真理的方式,
to start a way of talking about mathematical truths formally
这带来了公理化方法, 也带来了各种的所有的现代数学,
That led to the axiomatic method.That led to sort of all of modern mathematics,
找出一种方式来精确地谈论所谓的说明性知识(declarative knowledge), 什么是真的.
figuring out a way to talk precisely about so-called declarative knowledge, what is true.
同样地, 将来人们回顾这一切时会说, 是的, 那些 20 世纪的原始人摆弄着这些名为计算机的小玩意 . 但他们真正在做的是: 开始学着怎样**形式化(formalize)关于过程(process)**的直觉, 如何做事情.
but really what they were doing is starting to learn how to formalize intuitions about process, how to do things
**小编注: **process 在正式的计算机领域, 名为"进程", 这里译成"过程"是采用它的一般含义.
开始发展出一种方式来精确地谈论**如何做(how-to)的知识, 与此相对, 几何学谈论的则是"什么是真**".
starting to develop a way to talk precisely about how-to knowledge, as opposed to geometry that talks about what is true.
what is true 与 how-to 的具体区别, 我们来看一个具体的例子, 关于"根号X(√X)"的例子.
对于说明性知识而言, "√X"是这样一个数 "Y", 使得 Y2=X, 并且 Y ≥ 0;
更具体而言, 就是比如: √16=4, 因为 42=16, 并且 4 ≥ 0;
然而, 它并没有告诉我们如何从 16 得到 4.
与说明性知识不同, 过程性知识精确地描述了如何从 16 得到 4 的所有过程. 对于具体怎么求根号, 以下是一个过程性的描述:
为求得一个接近 √X 的值:
- 先猜测一个值 G(guess).
- 通过求 G 和 X/G 的平均值来改进猜测, 即(G+X/G)/2.
- 不断重复改进猜测的过程直到达到所要求的精度.
- 把 1 作为最初的猜测值.
以上方式称为"连续平均法求平方根(successive averaging)".
这一算法来自古希腊亚历山大城的数学家海伦(Heron of Alexandria)
我们来看一个具体的例子, 求根号2的值.
- 1 作为最初的猜测值, 但12=1, 比 2 小太多, 显然不满足;
- 然后在 1 的基础上改进猜测, (1+2/1)/2, 也即是 1.5 去做第二次猜测. 1.52=2.25, 又太大了;
- 继续在 1.5 的基础上改进猜测, (1.5+2/1.5)/2, 也即是 1.4166 去做第三次猜测. 1.41662=2.0067, 稍大了点, 但已经很接近 2 了;
- ...
- 定义一个截止的精度, 比如 0.001, 当与 2 的差值在这个精度以内就结束猜测.
代码如下: (视频截图)
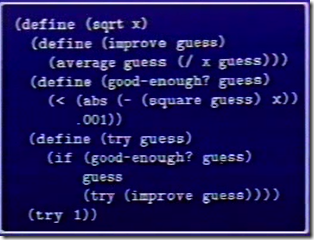
视频中用的语言是比较偏门的 lisp 的一个方言 scheme.
这里提供一个 Java 版本的实现:
package org.jcc.core.cs;
public class Sqrt {
public static void main(String[] args) {
System.out.println(sqrt(2));
}
public static double sqrt(double x) {
return tryGuess(x, 1);
}
private static double tryGuess(double x, double guess) {
if (goodEnough(x, guess)) {
return guess;
} else {
return tryGuess(x, improveGuess(x, guess));
}
}
private static double improveGuess(double x, double guess) {
return (guess + x / guess) / 2;
}
private static boolean goodEnough(double x, double guess) {
return Math.abs(guess * guess - x) < 0.001;
}
}
在 14 行 return guess 处打一个断点, 可以看到收敛很快, 4 次递归就达到了 0.001 的精度.
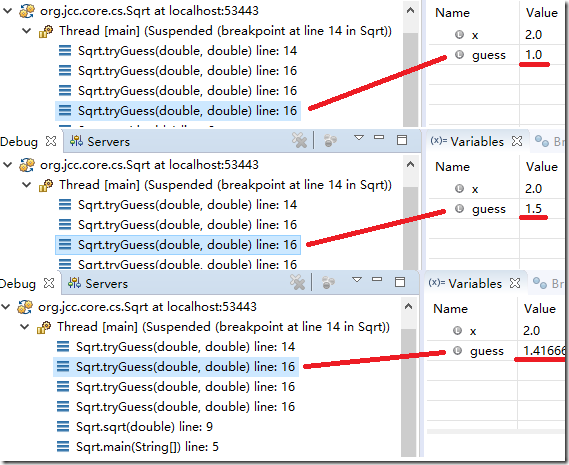
类似二分查找, 是指数衰减, 即使是求根号 1000, 也就 9 次左右的递归.
读者可以自行验证, 以上代码可见: demo of sqrt
通过以上对比, 我们现在清楚了说明性知识和过程性知识的不同, 也知道了计算机科学就是形式化这种 how-to 的过程性知识的行当, 如何去做一件事.
当然, 我猜有同学会问, 难道就这样吗? 这有什么值得说的吗? 的确, 如果所谓的计算机科学只是关于求个根号啥的, 那的确没有什么值得一提的.
真正的问题来自于当我们试图构建非常非常巨大的系统时, 那些成千上万行的计算机程序, 如此之长以至于没有人能够将它们全部放入自己的大脑中.
The real problems come when we try to build very, very large systems, computer programs that are thousands of pages long, so long that nobody can really hold them in their heads all at once.
使这些成为可能的唯一原因是我们有**控制这些大型系统复杂性的技术. **
And the only reason that that's possible is because there are techniques for controlling the complexity of these large systems.
这些控制复杂性的技术是这门课程所真正关注的, 在某种意义上, 那才是真正的计算机科学.
And these techniques that are controlling complexity are what this course is really about. And in some sense, that's really what computer science is about.
事实上, 对复杂性控制的关注并不局限在计算机科学上,
比如一架大型客机就是一个极端复杂的系统, 设计这一系统的空气动力学工程师需要处理巨大的复杂性.
但这种复杂性与计算机科学的复杂性有一些不同, 在某种意义上, 计算机科学不那么真实.
工程学面对客观的物理系统, 需要处理误差, 近似, 噪音等等问题;
计算机科学则与理想组件打交道( Computer science deals with idealized components),
不需要担心误差什么的, 也不用担心级联了太多部件后, 信号淹没在了噪声中.
也即是说, 在构建一个大型的程序时, 你所能构建的与你所能设想的之间并没有什么大的区别.
And that means that, in building a large program, there's not all that much difference between what I can build and what I can imagine,
构建大型软件系统的唯一限制是我们的想象力本身!
the constraints imposed in building large software systems are the limitations of our own minds.
前面说到, 教授不认为计算机科学是科学, 在这里, 他认为计算机科学像是一种抽象形式的工程学.
computer science is like an abstract form of engineering.
那么如何控制复杂性呢? 教授粗略列举了三大技术, 分别是黑盒抽象, 通用接口以及元语言抽象.
把具体实现封装在黑盒子里以压制细节的表达, 用户只需关心输入输出.
小编注: 这个原则在硬件方面的应用早就是非常普遍的, 我之前写的一个 简易计算机系列 在很多的地方都体现了这个原则.
关于如何连接各个组件(ways of plugging things together), 视频中没有展开叙述太多, 大概类似于我们一般说的面向接口编程, 模块化之类的技术.
小编注: 其实这方面硬件方面依然能带给我们很多的启发, 比如电脑, 手机的很多部件都是高度模块化, 通过很多的标准接口连接起来, 有些还能支持热插拔, 比如鼠标.
视频中也没有太多展开, 大概类似于我们一般说的"领域模型"和"领域语言"之类的.
比如 HTML, CSS 就可以视作为某些具体领域的语言.
如果有兴趣, 可以自行去看视频及一系列后续的视频.
不过视频中的 scheme 语言有点偏门, 很多例子也比较偏重数学方面.
好了, 关于计算机科学的介绍就到这里.
Don’t Repeat Yourself, 不要重复你寄己~
很遗憾, 标题本身就重复了, "Don’t Repeat Yourself"与"不要重复"语义是一样的, 但是是两种不同语言的实现. (英文和中文~)
在软件开发的实践中, 有许多的原则与模式, 如果挑选其中一些最为重要的出来, DRY 可算一个.
DRY 意为"Don’t Repeat Yourself", 简单讲就是"不要重复", 可以这么说, 管理重复性是软件开发活动中极为重要的一项内容.
在计算机科学中, 复杂性管理是最重要的一个主题, 而复杂性的一个重要来源就是从一个个看似简单不起眼的重复开始的.
我们经常说"量变导致质变", 确实, 只是有最后一根稻草是不足以压垮骆驼的, 它一定是一个累积的效果.
It is the last straw that breaks the camel's back, 压垮骆驼的最后一根稻草常常作为最终的背锅侠出现, 有个笑话说"一个饿汉吃到第三个饼才吃饱, 然后后悔自己花钱买了前两个饼..."
哪怕是简单的重复, 积累起来也会形成巨大的复杂性, 最终导致事态失控.
为此, 我们要在最开始的实践中就要注重消除出现的重复, DRY 原则初看来似乎很简单, 但展开之后我们会发现, 有相当多的实践都与这一原则有莫大关系.
我一向不喜欢抽象的去说理, 但展开讲的话, 单单这一个篇幅是不够的, 这里只作为一个引子, 在后面, 我会举出很多具体的事例与实践来论证这一点.