
让我们从一个故事开始说起. 话说北大是很有哲学传统的, 当你准备踏进北大校门时, 连门卫都会连问你三个终极哲学问题:
你是谁? 你从哪里来? 你要到哪里去?
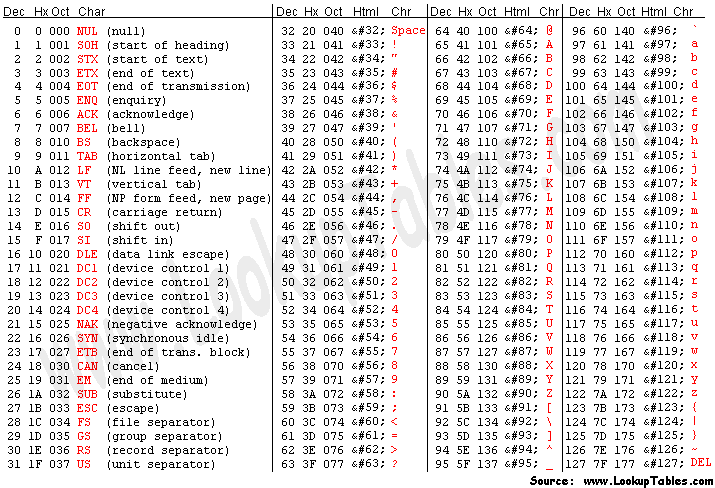
那么这与我们的问题又有何关系呢? 我觉得理解内存中的编码的关键在于理解 String 类型, 因此我们也来探讨一下 String 的前世今生:
- String 是谁(什么)?
- String 从哪里来?
- String 到哪里去?
当我们能够清晰地回答这三个终极问题时, 对文本在内存中的编码也算理解得差不多了.
注: 文中将用 Java 平台为例来探讨这些问题.
{kind=link}