
在上一篇章中谈论了表单以 get 提交时的编码与乱码问题, 这一章中将讨论以 post 方式提交时的编码与乱码问题.
在前面也同时提到, 表单有一个叫 enctype 的属性, 它有两个值, application/x-www-form-urlencoded 和 multipart/form-data.
这一属性实际只对 post 方式起作用, 因为 get 方式实际只支持前一种类型, 也就是 application/x-www-form-urlencoded, 这是缺省的类型.
在使用 post 方式提交时, 缺省的编码类型也依然是这个 application/x-www-form-urlencoded. 在这一篇章中, 先讨论这一类型;在下篇中, 再讨论 multipart/form-data 类型.
post 方式, application/x-www-form-urlencoded 类型的编码
对于 application/x-www-form-urlencoded 类型, 前面讨论 get 的方式已经详细讨论过了, post 方式用它, 底层原理依旧是相同的, 只不过它的数据此时不是放在 uri 中, 而是在 消息体 中发送过去.
简单地讲, 就是地址栏中是看不出来的.
发送形式有差别, 但在这里关心的编码方式上, 却与 get 是一样的. 比如, 非字母数字的字符要用转义表示, 键值对用等号隔开, 多个键值对用 "&" 符号拼接.
对于要转义的字符, 在编码的使用上, 也是一样的:
- 没有用 accept-charset 指定, 就用文档本身的编码;
- 设置了 accept-charset 的值, 就用它设置的值.
稍微要注意的反而是后台的接收方面.
一个具体的例子
依旧是构建一个简单的 post 方式提交的表单:
<!DOCTYPE html><html><head>
<meta charset="UTF-8">
<title>表单 post 提交页(页面编码 utf8)</title>
</head><body>
<h2>post 提交, 页面编码: UTF-8</h2><hr>
<form action="form_post_target_default.jsp" method="post">
<input name="english" value="hi">
<input name="chinese" value="你好">
<input type="submit" value="submit"></form>
</body></html>
然后提交到一个后台的 jsp 上, 依旧是简单地取出显示:
<%@ page pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<title>表单 post 接受页(缺省)</title>
</head>
<body>
<h3>request keep default</h3>
${param.english} ${param.chinese}
</body>
</html>
提交后会发现这样的方式地址栏将不会再有 "查询字符串(query component)" 了:
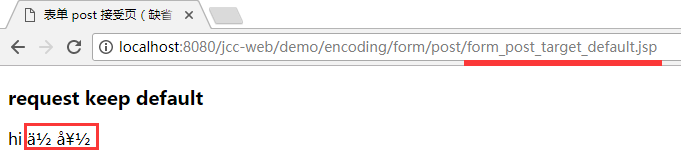
但能注意到接收页面的显示是乱码的. 此时查看请求头的信息:
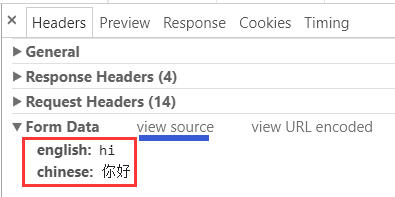
表单数据是正常的, 点击 view source, 发现确实是 utf-8 的转义编码:
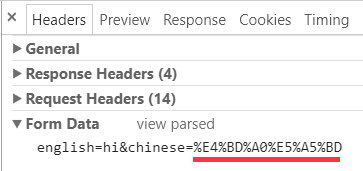
整体上也是 urlencoded 的方式, 跟上篇说到的 get 一样, 因为还是缺省的 application/x-www-form-urlencoded 方式的编码.
后台用 setCharacterEncoding 设置解码字符集
所以, 整个发送环节是没有问题的, 问题出在后台接收处理上. 因为数据不是在 uri 中, 自然之前的所谓设置 URIEncoding 是没有用了, 这时需要不同的策略.
post 情况下, 在取出数据前, 就 java servlet 平台而言, 需要用 request.setCharacterEncoding("utf-8") 先设置一下, 编码的具体值与浏览器所用的一致即可, 因为表单用的是 utf-8, 这里也就设置为 utf-8, 像这样:
<%@ page pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<title>表单 post 接受页(utf-8)</title>
</head>
<body>
<h3>request.setCharacterEncoding("utf-8")</h3>
<%request.setCharacterEncoding("utf-8"); %>
${param.english} ${param.chinese}
</body>
</html>
调整之后, 再测试就正常了:
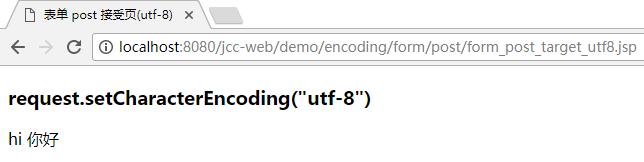
假如没有作这一步骤的设置, 那么 servlet 中将使用缺省的 iso-8859-1 来解码.
在某些情况下, 如果你无法在这一层面进行调整, 也可以保持按 iso-8859-1 的方式来接收, 然后使用一种 hack 的方式来倒腾出正确的 string 的值, 具体见 文本在内存中的编码(3) 中的介绍, 这里不再详述.
一般来说, 除非不得已, 不太建议使用 hack 的方式.
使用 accept-charset 属性指定 post 时的编码
假如表单页面增加 accept-charset 字段, 值设为与文档本身编码 utf-8 不一样的 GBK:
<!DOCTYPE html><html><head>
<meta charset="UTF-8">
<title>表单 post 提交页(页面编码 utf8)</title>
</head><body>
<h2>post 提交, 页面编码: UTF-8</h2><hr>
<form action="form_post_target_utf8.jsp" method="post" accept-charset="gbk">
<input name="english" value="hi">
<input name="chinese" value="你好">
<input type="submit" value="submit"></form>
</body></html>
那么这样之后, 提交的数据就是 GBK 编码了, 不是 utf-8 编码的情况下调试工具中无法正常为字符:
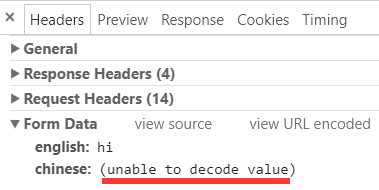
不过点击 view source, 还是可以看到原始的值:
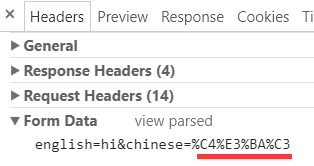
四个字节确实为 gbk 编码.
而后台的解码此时也会再一次出现问题:
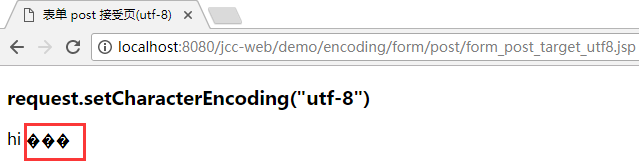
因为提交数据的实际编码是 gbk, 而后台代码却还是按 utf-8 来解码, 所以就出错了. 而调整方式也很简单, 就是把 request.setCharacterEncoding("utf-8") 改为 request.setCharacterEncoding("gbk") 即可, 改完后的代码及具体测试这里就不再列出了, 读者可以自行实验.
总之, 一句话, 编码与解码两端要在使用的字符集编码上保持一致即可.
配置 filter 统一解码时所用的字符集
如果不想在每次接收前都来调用 request.setCharacterEncoding 这么设置一下, 可以统一配置一个过滤器, 以 tomcat8 为例, 可以这样在 web.xml 中去增加一个 filter, 并在初始化参数 init-param 下设置参数名 param-name 为 encoding, 设置参数值 param-value 为 UTF-8:
<filter>
<filter-name>Character Encoding Filter</filter-name>
<filter-class>org.apache.catalina.filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>Character Encoding Filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
这样就统一设置为使用 utf-8 来解码了.
如果你不是使用 tomcat, 或者 tomcat 的版本太旧不包含上述 filter, 那么也可以自行定义一个类似的 filter, 原理上简单讲就是在 doFilter 方法里设置一下编码:
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
request.setCharacterEncoding("utf-8");
chain.doFilter(request, response);
}
更复杂完善一点的可以先看看 request 中是否已经设置过了 charset.
许多的 MVC 框架中关于编码的设置其实就是着力在这里.
关于 Filter 方面不了解的读者可以自行阅读 servlet 相关规范以了解.
当然了, 这样之后, 表单就不能用 gbk 编码方式来提交了. 如果你有一些遗留的 gbk 页面, 那么就要在其表单上设置 accept-charset="utf-8", 指示它用 utf-8 来编码提交的数据.
注意: 如果你不太确定这种统一的调整会造成哪些冲击, 那么就要慎重地去处理, 特别是在运行已久的遗留系统上, 可能还存在前面提到的各种混乱的 hack 的处理方式, 统一的调整可能会使得这样的代码失效.
这也是不提倡使用 hack 的原因, 它代表了一种不太正确的处理方式, 并给后续的调整带来了挑战, 后来者往往只能"将错就错", 继续地 hack 下去.
那么, 关于 post 方式以 application/x-www-form-urlencoded 的类型来提交时的编码与乱码问题, 因为与之前的 get 方式提交还是很相似的, 这里就简单介绍到这里.